ARTICLES
A handy new Google Cloud, AWS, and Azure product map | 9 min | Cloud | Stephanie Wong | Google Cloud Blog
Google published a product map, showcasing similar offerings between Google Cloud, AWS and Azure. You can easily filter the list by product name or other common keywords. This table can make it easier for you to quickly find similar products from each provider.
The 5 most important recent developments in AI | 6 min | AI | Dovydas Ceiltuka | Turing College Blog
- Minerva (Google) - Minerva is a language model capable of not only solving maths and science problems submitted in the form of natural language, but also of providing its reasoning behind the answer.
- No Language Left Behind (Meta AI) - a massive number of languages it’s able to translate between. Specifically, that number is 200, which amounts to 40,000 language combinations in total!
- Whisper (Open AI)
- Stable Diffusion (Stability AI)
- Make-a-Video (Meta AI)
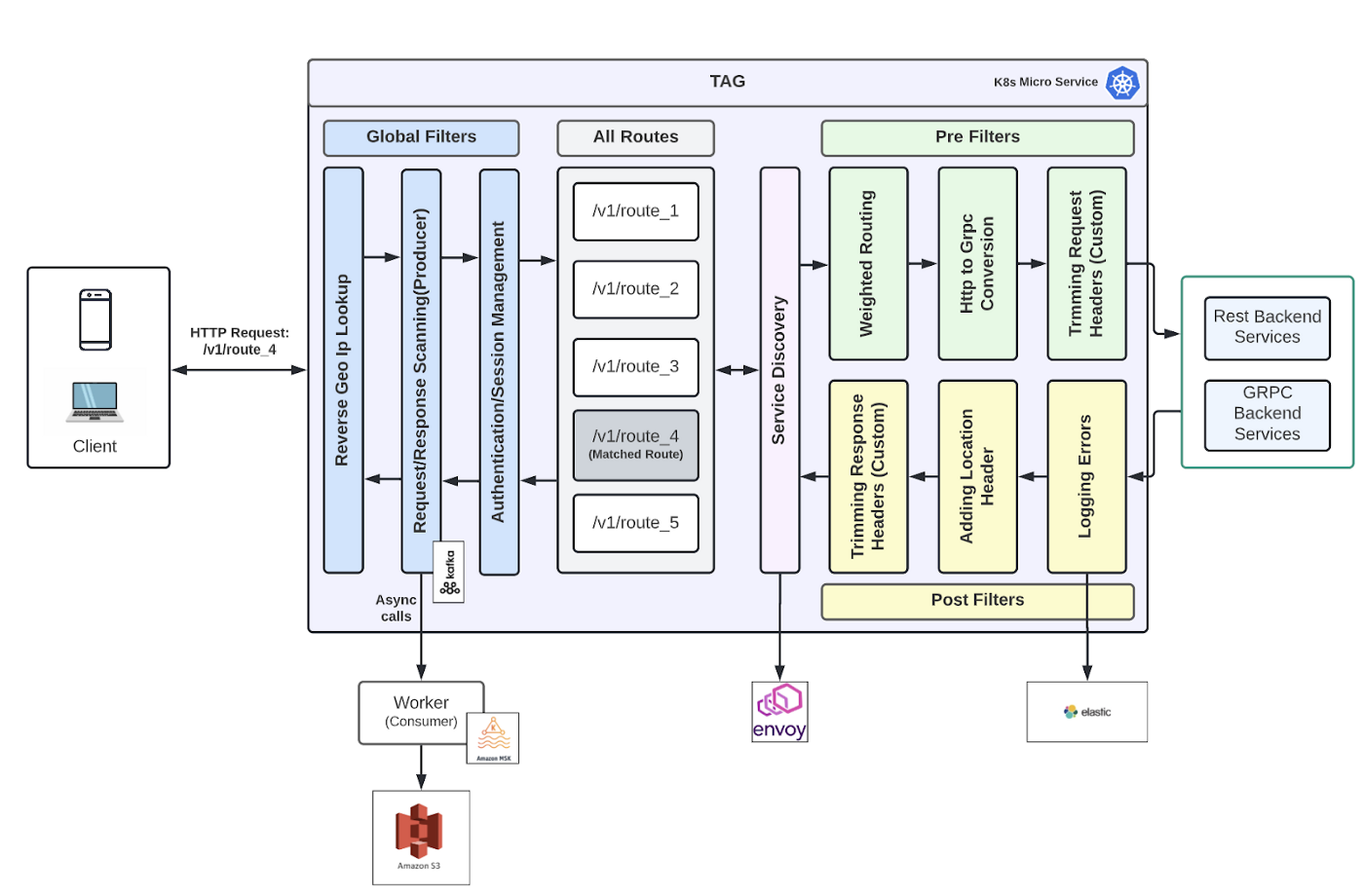
How we built the Tinder API Gateway | 7 min | API Gateway | Vijaya Vangapandu, Siva Periyasamy, Nishant Mittal & Tejas Nomulwar | Tinder Blog
The Tinder API Gateway (TAG) is one of the critical frameworks at Tinder that solves the need for exposing public APIs and enforcing strict authorization and security rules.
Tinder needed:
- A solution to bring all external facing services under one umbrella
- An artifact that could be used by any application team to spin off their API Gateway to scale their application independently
- A framework that could provide the capability for applications to run as a Kubernetes microservice along with other Kubernetes services
Query Rewards: Building a Recommendation Feedback Loop During Query Selection | 4 min | Data Engineering | Bella Huang, Raymond Hsu & Dylan Wang |
Pinterest Engineering Blog
How do you select the right query pins from the user’s profile?
We added a new component to the Query Selection layer called Query Reward. Query Reward consists of a workflow that computes the engagement rate of each query, which we store and retrieve for use in future query selection. Therefore, we can build a feedback loop to reward the queries with downstream engagement.
How We Use Terraform At Slack | 15 min | Data Engineering | Archie Gunasekara | Slack Engineering Blog
Slack uses Terraform for managing Infrastructure, which runs on AWS, DigitalOcean, NS1 and GCP. They chose Terraform as opposed to using an AWS-native service such as CloudFormation to use a single tool across all of our infrastructure service providers. This keeps the infrastructure-as-code syntax and deployment mechanism universal.
All of our Terraform pipelines run on a set of dedicated Jenkins workers. These workers have IAM roles attached to them with sufficient access to our child accounts so that they can build the necessary resources. However, engineers at Slack also needed a place to test their Terraform changes or prototype new modules. This place has to have an identical environment to the Jenkins workers without the same level of access to enable the modification or creation of resources. Therefore we created a type of box called “Ops” boxes at Slack, where engineers can launch their own “Ops” box using a web interface.
Search Pipeline: Part I | 8 min | Search and Relevance | Stuart Cam | Canva Engineering Blog
This article lies on the crossroads of machine learning, data science, operations, backend and frontend. It’s about why Canva needs to build a scalable search architecture and where the problems were with previous architecture.
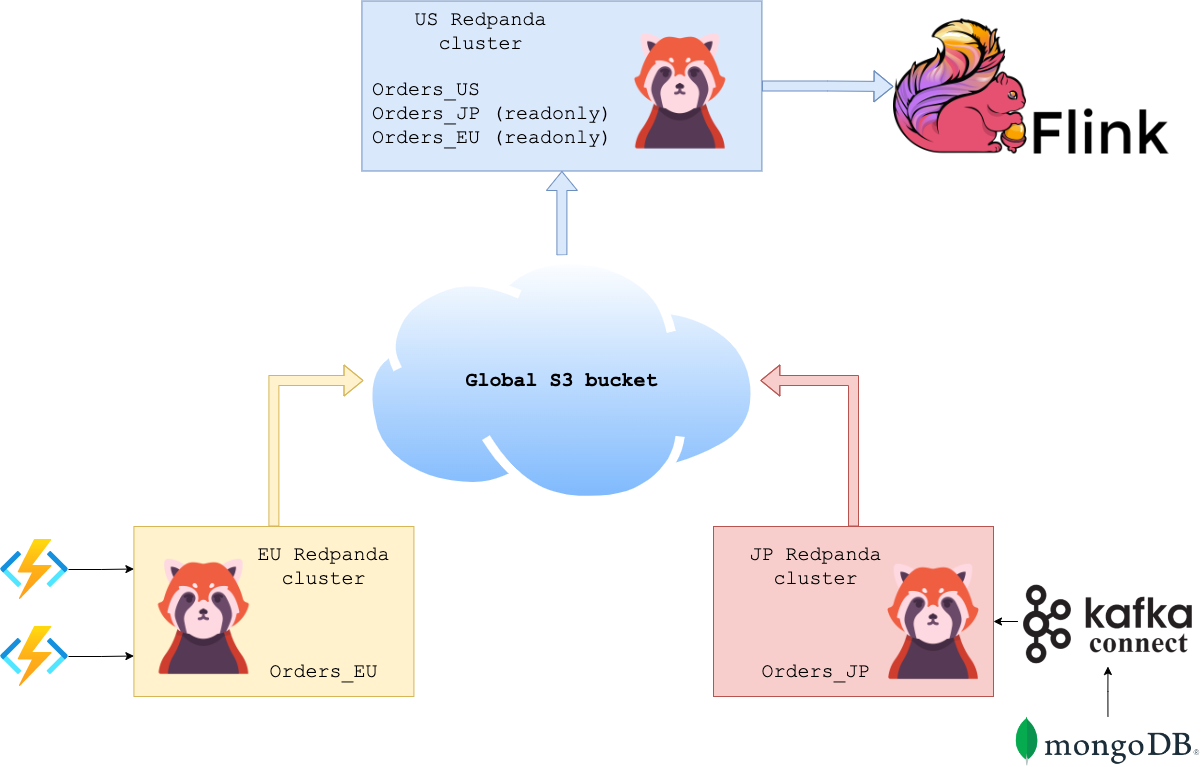
A closer look at Redpanda. Is it worth using Kafka anymore? | 6 min read | Kafka | Adrian Bednarz | TechWithAdrian Blog
Redpanda is a Kafka-compatible streaming platform that aims to unify historical and real-time data processing. Additionally, as Adrian demonstrates in his article, Redpanda can be a serious competitor to Kafka (even more than Pulsar).
If you have ever maintained a large-scale Kafka cluster then you know how painful this can be. Redpanda on the other hand may have some advantages, like:
- scales well both vertically and horizontally. All code-level optimizations yield predictable and low latency values. The Redpanda team claims up to 10x better latency overall with about 40x better p99 latency.
- Support shadow indexing
- Built-in schema registry
- You can use existing solutions such as Kafka Connect with Redpanda
Do not use ‘git checkout’ anymore | 1 min | GitHub | TheDevStory Blog
‘Git switch and Git restore’ is a command that Git has added in Git 2.23. It works similarly to the checkout command. But not exactly the same.
Two new commands:
- switch: switch branches
- restore: Restore working tree files
You can now write commands specifically for situations that are much more appropriate.
Improving Instagram notification management with machine learning and causal inference | 8 min | ML | Nailong Zhang | Engineering at Meta Blog
An example of how Instagram used causal inference and ML to control sending daily digest push notifications.
By applying model and targeting the users + notifications with high incremental impact, we reduced the sending volume substantially compared to using the CTR model and also saw no decline in user engagement.
BIZ & MANAGEMENT
How Big Tech Runs Tech Projects and the Curious Absence of Scrum | 17 min | Project Management | Gergely Orosz | Pragmatic Engineer Blog
This article starts with the story of the battle between Skype and WhatsApp on the communication app market. One of them uses scrum, the other doesn't.
The moral of the story is that the chosen framework may not be crucial to the success of projects. There are other factors.
However, it is no coincidence that in Big tech there is a lack of scrum at the carer.
In many companies, teams have autonomy in choosing the best work methodology.
Also, the Project Manager role is now different.
This article analyzes this in the example of 100 companies.

Building systems at scale: how Skyscanner approaches engineering design reviews | 5 min | Project Management | Tom Butterwith | Skyscanner Engineer Blog
One of our engineering principles at Skyscanner is that we peer-review every change and we apply this principle to everything from one-line code changes to system design.
Often the most difficult part of building systems at scale is aligning your stakeholders, and setting the scene up front in a design document is a great way to bring people along in your process.
NEWS
Improved text analytics in BigQuery: search features now GA | 6 min | Data Analytics | Christopher Crosbie & Huong Phan | Google Cloud Blog
Google has announced the general availability of search indexes and search functions in BigQuery. This combination enables you to efficiently perform rich text analysis on data that may have been previously hard to explore due to the siloing of text information
DATA TUBE
Sarah Maston, Project 15 | 1 h | Data | Hackster Café
An interview with Sarah Maston,the founder of Microsoft's Project 15 – lowering costs, complexity and time-to-launch for conservation and ecosystem sustainability projects with the latest IoT technologies on an open source software platform.
PODCAST
Building Safe and Reliable AI applications | 30 min | AI | hosts: Ben Lorica; guests: Christopher Nguyen | The Data Exchange Podcast
Christopher Nguyen, CEO and co-founder of Aitomatic, a startup that uses a knowledge-first approach to build and deploy machine learning solutions, shares:
- Knowledge-first AI: what, why, how.
- The relationship between data-centric AI and knowledge-first AI.
Data Analyst, Data Scientist, and Data Engineer Career Paths | 1h 13 min | Data Science and Cloud | hosts: Jon Krohn; guests: Shashank Kalanithi | Super Data Science Podcast
- how Shashank got started producing YouTube videos on data science,
- the essential differences between data science roles
- how data could shape the future of the sports industry.
CONFS EVENTS AND MEETUPS
Data-driven Fast Track: introduction to data drivenness | 23 November | Online free webinar
You will take a glance at our 3-step framework for data-driven transformation. You will learn how to:
- assess the data-driven your company today
- generate ideas for new initiatives to push your company towards better decisions
- think about implementing these initiatives to increase your chances to succeed
Big Data Conference Europe | 23-24 November | Online
Two day’s with technical talks in the fields of Big Data, High Load, Data Science, Machine Learning and AI.
- You Are Overthinking Data Quality with Steve Upton
- MLOps: Scaling TensorFlow Model on Kubernetes with Andrej Baranovskij
- An Advanced Data Platform to Drive User Engagement with Daniele Montesi and Emanuele Viglianisi
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub