

ARTICLES
How to Build Data Analytics Using LLMs in Under 5 Minutes | 5 min | Patrik Braborec | GoodData Developers
GoodData has been a driving force in the data analytics scene, and now they're taking the lead in the LLMs era. They're making things more intuitive by automating analytics and letting users chat with their data in plain English. It's a game-changer, eliminating the need for technical know-how when asking questions and setting a new, user-friendly standard for data querying.
How to use LLMs for data enrichment in BigQuery | 16 min |Piotr Pilis | GetInData | Part of Xebia Blog
A comprehensive guide on how individuals can leverage LLMs and BigQuery to bring additional value to data and boost analytical capabilities. Use cases, architectural considerations, implementation steps and evaluation methods to ensure that readers are fully equipped to use this powerful combination in their own data processes.
LMQL — SQL for Language Models | 17 min | Mariya Mansurova | Towards Data Science Blog
This article explores LMQL's advantages in addressing challenges faced by LLMs, such as interaction complexity and token representation constraints. While acknowledging some limitations, the article touches on LMQL's potential benefits in offering nuanced control over output and reducing costs. Practical examples demonstrate LMQL's syntax and application in sentiment analysis tasks, using local models like Zephyr and Llama-2-7B, concluding with a nuanced evaluation of LMQL's performance and role in Language Model Programming.
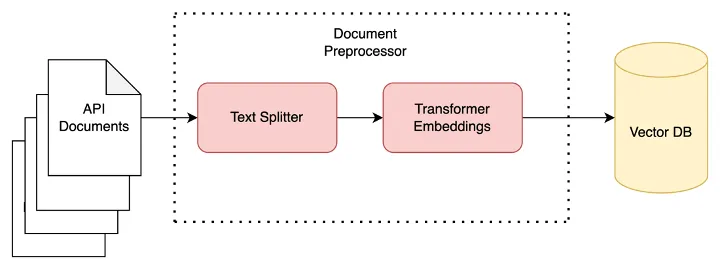
Conversational Bot for Enterprise APIs using LLM Agents, VectorDB and GPT4 | 6 min |Lakshya Khandelwal | Walmart Tech Blog
Intricacies of the solution, exploring the integration of LLMs, LangChain and Vector DBs to create a powerful platform for discovering and extracting information from APIs using natural language.
Getting the Most from LLMs: Building a Knowledge Brain for Retrieval Augmented Generation | 14 min | Abhinav Kimothi | MLearning.ai
This article addresses the challenges in real-world LLM applications, focusing on knowledge limitations and hallucinations. It introduces RAG as a solution, enhancing LLMs with extra context for improved accuracy. The work explicitly explores the crucial steps in the Indexing Pipeline—loading, splitting, embedding and storing knowledge sources.
TUTORIALS
Running Mixtral 8x7b locally with LlamaIndex | 6 min | LlamaIndex Blog
Dive into the release, Mixtral 8x7b, which has stirred excitement by demonstrating its capabilities comparable to or surpassing GPT-3.5 and Llama2 70b on various benchmarks. LlamaIndex provides a step-by-step guide to incorporating Mixtral into your local environment. Explore how Mixtral can be seamlessly integrated into LlamaIndex, allowing you to harness its potential and run powerful AI models locally.
Dataset enrichment using LLM’s | 7 min | Jeroen Overschie | Xebia Tech Blog
This tutorial explores 3 strategies on how to use LLMs for extracting structured data from a piece of text by:
- providing a JSON example,
- defining a Pydantic schema (also see this blogpost),
- using OpenAI's Function Calling API.
Serverless compute for LLM — with a step-by-step guide for hosting Mistral 7B on AWS Lambda | 6 min | LLM | Rustem Feyzkhanov | AWS in Plain English
This article tackles the challenges of deploying LLMs in production, comparing hosting options like GPU-based solutions, LLMaaS services, CPU web servers and serverless computing, particularly on AWS Lambda. It delves into the specifics of using serverless computing for LLMs, discusses limitations such as cold start times and prediction speeds, and provides a step-by-step guide for deploying the Mistral 7B model to AWS Lambda using LLAMA.CPP with OpenBLAS support.
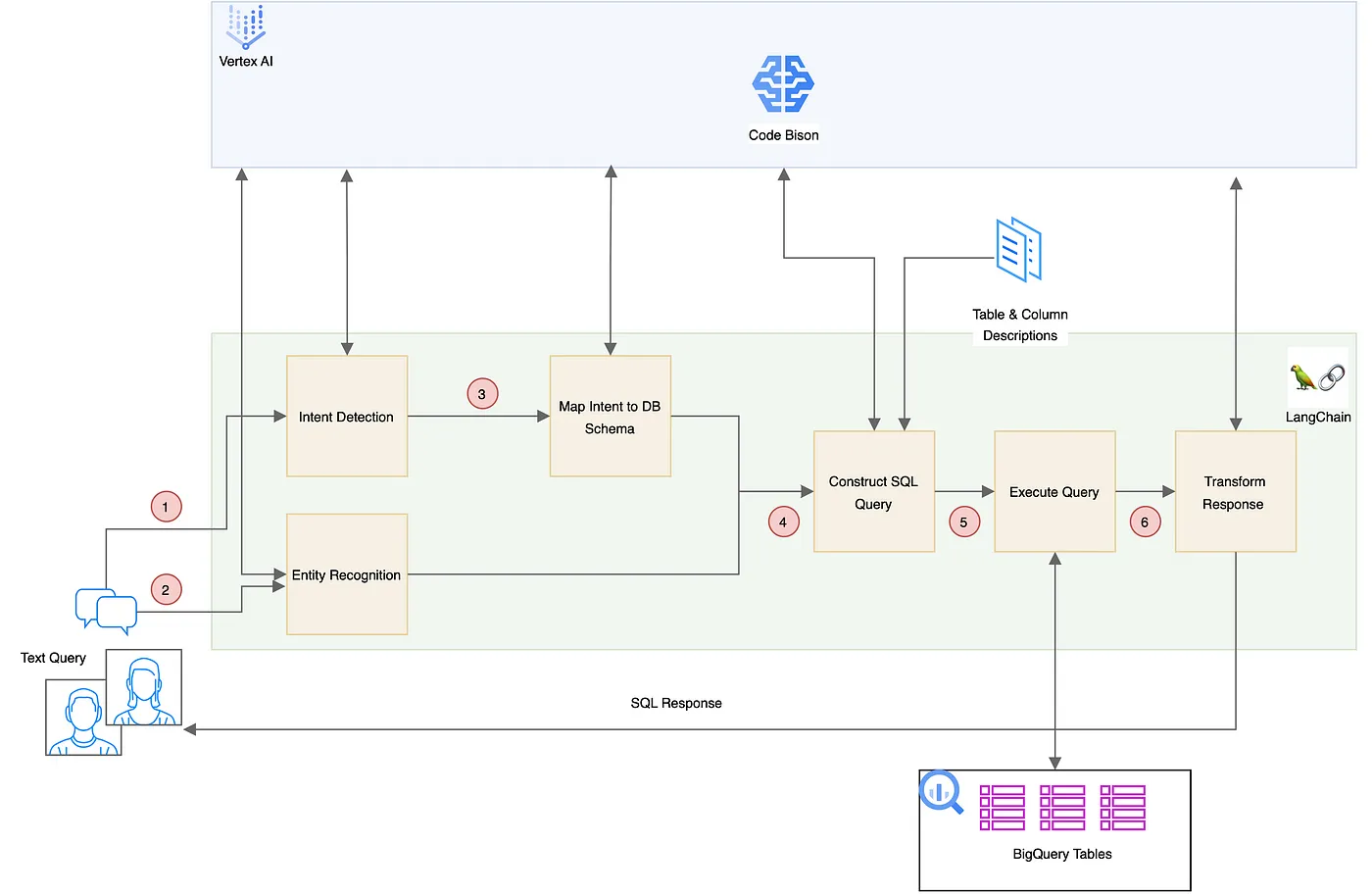
Architectural Patterns for Text-to-SQL: Leveraging LLMs for Enhanced BigQuery Interactions | 36 min | SQL | Arun Shankar | Google Cloud - Community Blog
Read about the Text-to-SQL domain, focusing on the growing reliance on LLM and its partnership with Google's BigQuery for improved SQL query generation. It showcases practical demonstrations, including a case study on the travel industry, illustrating how LLMs interpret user requests and interface with BigQuery for precise SQL commands. It also discusses five architectural patterns for Text-to-SQL, providing insights into their pros and cons and practical demonstrations using datasets and executable code.
TOOLS
vLLM is a fast and easy-to-use library for LLM inference and serving.
Ollama is a tool for running AI models on your hardware. Many users will choose to use the Command Line Interface (CLI) to work with Ollama.
DATA TUBE
LlamaIndex Workshop: Multimodal + Advanced RAG Workhop with Gemini | 53 min | Cher Hu, Lawrence Tsang, Michael Chen | LlamaIndex
The Google Gemini release included both exciting multi-modal capabilities as well as semantic retrieval. In this workshop, we cover two cool LLM + RAG use cases with Google Gemini:
- Multi-modal RAG: Use the Gemini model to extract structured outputs from images. Then learn how to index these texts + images and build a QA system from it (also using Gemini).
- Advanced RAG: Learn how to use the brand-new Semantic Retrieval API. You can decompose it into different components - custom embedding-based retrieval and custom response synthesis.
PODCAST
Orchestration for LLM and RAG applications | 50 min | LLM | Ben Lorica and Malte Pietsch | The Data Exchange Podcast
Listen to the talk with Malte Pietsch, co-founder & CTO at Deepset who leads the development of Haystack, an open-source orchestration framework for Large Language Models (LLMs). This user-friendly tool streamlines the integration of LLMs, vector databases and document stores, making complex system development effortless.
Are LLMs the end of computer programming (as we know it)? | 22 min | LLM | Ben Popper and Ryan Donovan | The Stack Overflow Podcast
Ben and Ryan discuss how LLMs are changing the industry and practice of software engineering, a notorious Crash Bandicoot bug, and communication via a series of tubes.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
