
ARTICLES
How do we run Kafka 100% on the object storage? | 13 min | Data Engineering | Vu Trinh | The Deep Hub Blog
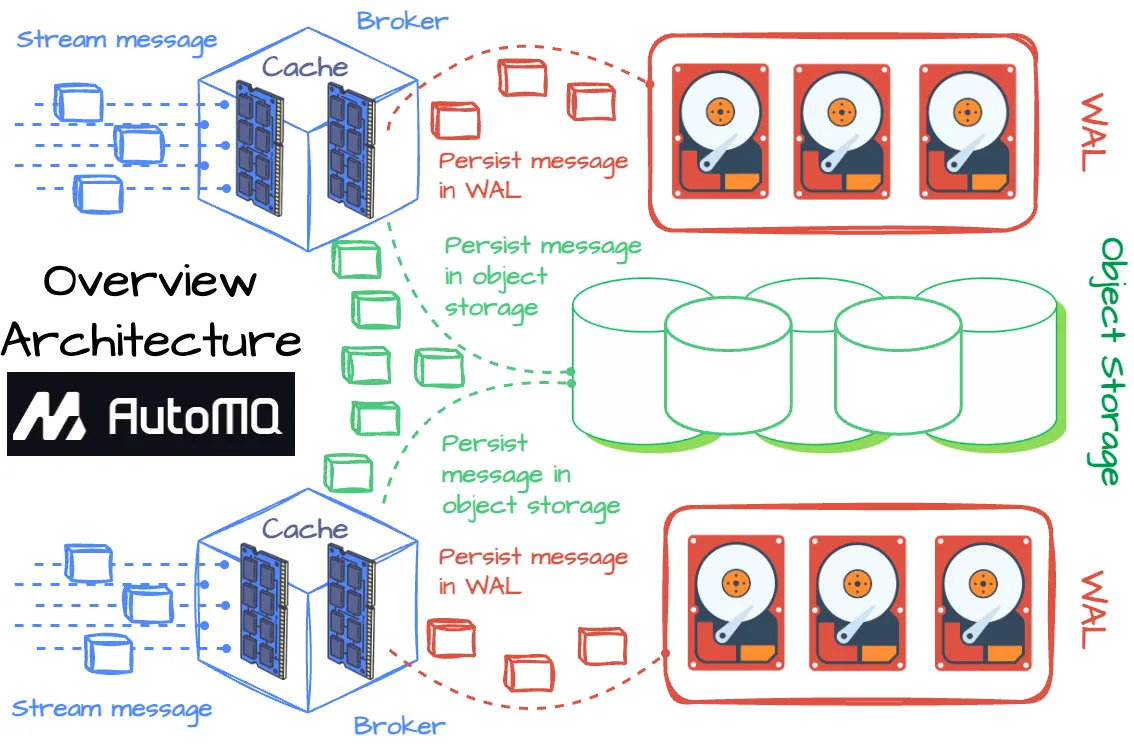
This article explains how AutoMQ makes Kafka entirely run on object storage, enhancing scalability and performance by separating storage from computing. It covers key aspects like cache management, Write Ahead Log (WAL), object storage, recovery processes, and metadata management.
How Much GPU Memory is Needed to Serve a Large Language Model (LLM)? | 4 min | LLM | Mastering LLM Blog
Understanding how to estimate GPU memory requirements is crucial for deploying Large Language Models (LLMs) like GPT or LLaMA. This article provides a formula to calculate the necessary GPU memory based on model parameters, precision, and overhead, ensuring efficient hardware utilization and avoiding bottlenecks during model deployment.
Why Did Databricks Open-Source Unity Catalog? | 6 min | Data Engineering | StarRocks Engineering Blog
Databricks open-sourced Unity Catalog to strengthen the open data ecosystem and highlight the maturity of lakehouse architecture. This move, alongside their acquisition of Tabular, is poised to significantly impact the data analytics landscape and boost the importance of open-source solutions.
TUTORIALS
Pinot for Low-Latency Offline Table Analytics | 16 min | Data Engineering | Ankit Sultana, Caner Balci | Uber Engineering Blog
Explore how Uber uses Apache Pinot for over 100 low-latency analytics use cases. Read about Pinot's integration with batch sources like Apache Hive, enabling high-performance queries on large datasets through a self-serve platform for seamless data ingestion.
Data Quality in Streaming: A Deep Dive into Apache Flink | 19 min | Data Quality | Maciej Maciejko | GetInData | Part of Xebia Blog
This tutorial delves into data quality in streaming systems, focusing on Apache Flink. It covers key aspects like completeness, uniqueness, timeliness, validity, accuracy, and consistency and how to implement them in a streaming architecture for high-quality data.
Kimball dimensional data warehouse modelling: enabling simplicity at scale | 7 min | Data Modelling | Taís Laurindo Pereira | Xebia Blog
Explore the Kimball dimensional modeling framework, its core concepts, lifecycle, and how modern tools like dbt can enhance the process.
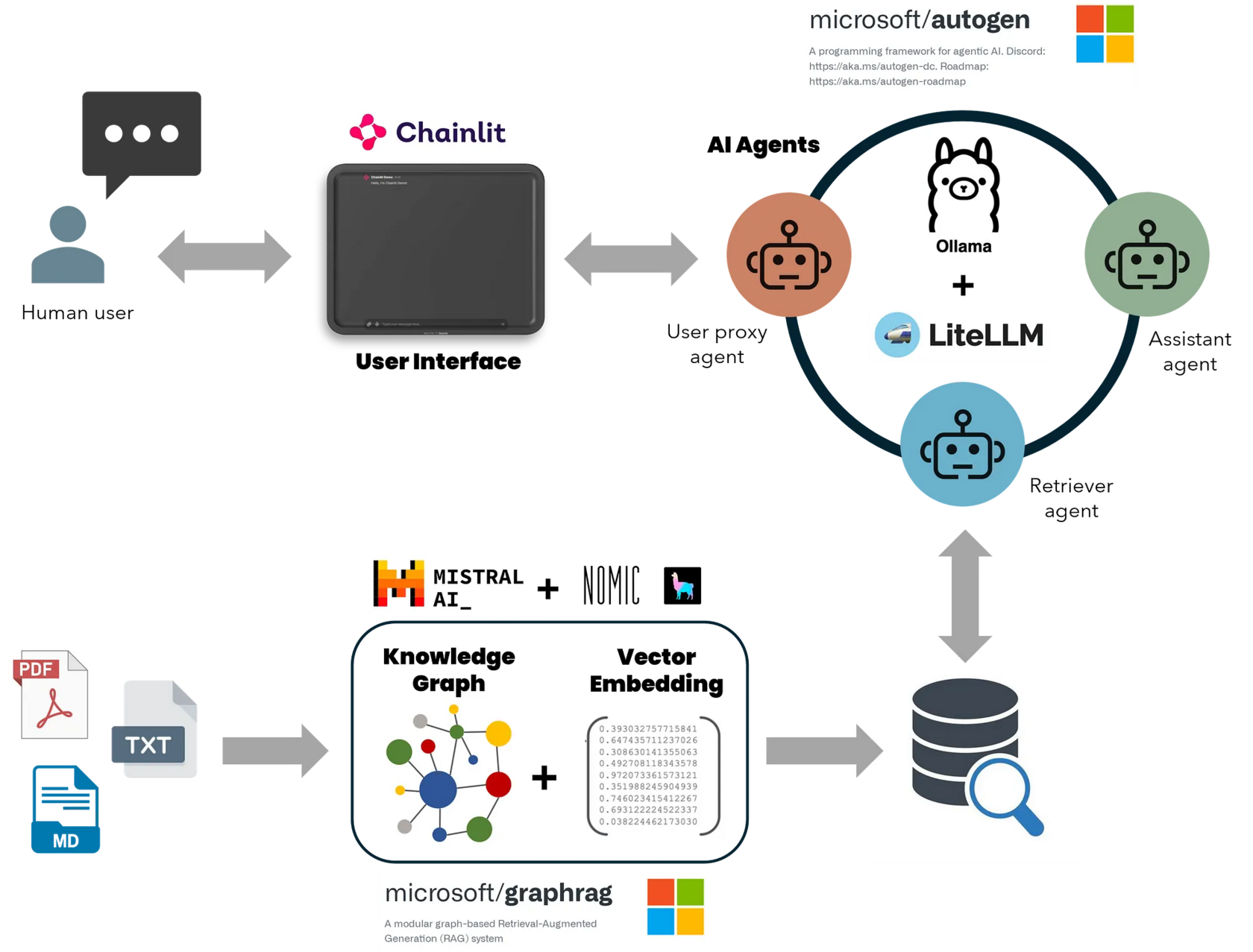
Microsoft’s GraphRAG + AutoGen + Ollama + Chainlit = Local & Free Multi-Agent RAG Superbot | 11 min | RAG | Karthik Rajan | AI Advances Blog
This article will guide you on constructing a multi-agent AI application with GraphRAG retrieval system, which operates entirely on your local machine and is available at no charge.
PODCAST
Generative AI in the Enterprise with Steve Holden, Senior Vice President and Head of Single-Family Analytics at Fannie Mae | 39 min | Gen AI | Adel Nehme, Steve Holden | DataFramed
In the episode, Adel and Steve explore generative AI opportunities, building a GenAI program, use-case prioritization, fostering an AI-first culture, skills transformation, governance as a competitive edge, scaling challenges, future AI trends, and more.
DATA TUBE
Dagster, SDF, & the Evolution of the Data Platform (A Dagster Deep Dive) | 42 min | Data Platform | Lukas Schulte, Pedram Navid | Dagster
Explore how the combined strengths of Dagster’s orchestration and SDF’s transformation capabilities can enhance your developer experience, streamline your data pipelines, reduce costs, and enhance data quality and reliability.
Key Takeaways:
- Unified Workflow Management: Seamlessly integrate and manage your data workflows.
- Enhanced Data Quality: Ensure consistent and reliable data through advanced transformation techniques.
- Improved Developer Experience: Experience lightning-fast execution and robust SQL validation with SDF
CONFS EVENTS AND MEETUPS
Harnessing DuckDB in the Cloud | Webinar | 13th September
Explore Motherduck's innovative features powered by DuckDB. Learn how it enhances the data stack, use cases, and upcoming integrations.
Data Mesh - Where Are We Now? | Webinar | 16th September
Zhamak Dehgani introduced data mesh principles five years ago to decentralize data ownership and improve scalability. Organizations have since experimented with this approach. Join a webinar to learn about early insights, practical versions, and tips for successful implementation.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
