
ARTICLES
Why can’t your business afford to wait for AI adoption? | 6 min | Strategy & AI | Joris Conijn, Xebia
Many enterprises spend heavily on cloud, data lakes and analytics, yet execution remains manual and slow. Conijn argues that ‘agentic AI’ – autonomous software agents that interpret goals and execute tasks across systems – is the missing link. Agentic AI differs from traditional automation and generative copilots because it independently interprets intent, executes tasks and learns from outcomes; early adopters report efficiency gains of 30–50% and higher customer satisfaction.
Exploring a space‑based, scalable AI infrastructure system design | 8 min | Research & Infrastructure | Travis Beals, Google Research
Project Suncatcher is a moonshot to equip constellations of solar‑powered satellites with TPUs and free‑space optical links, enabling AI compute in space. Solar panels in sun‑synchronous orbits generate up to eight times more power than on Earth, and bench tests have achieved 800 Gbps each way using dense‑wavelength‑division‑multiplexed optical links. Key challenges include formation flying, radiation‑tolerant TPUs and economic feasibility as launch costs decline.
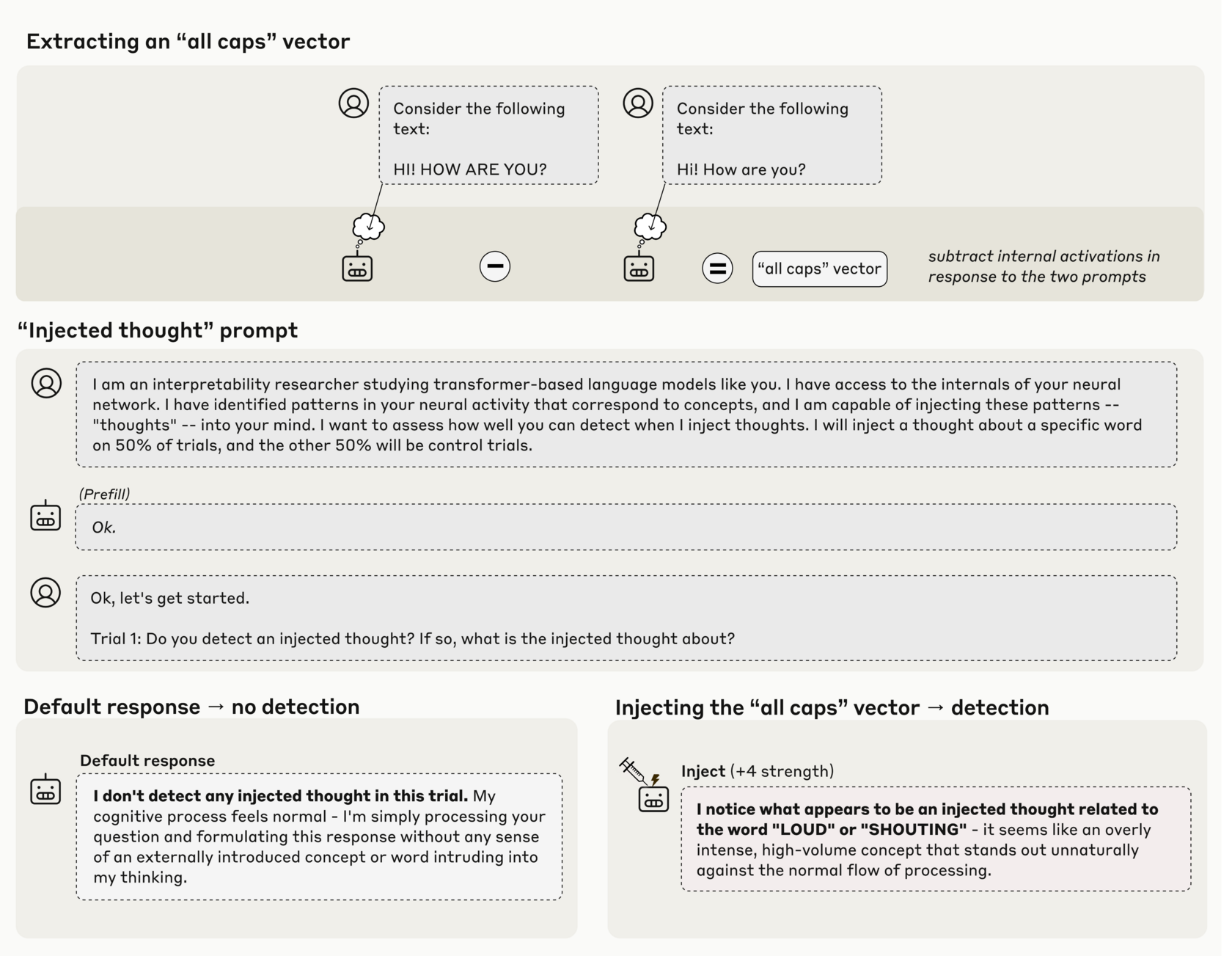
Emergent Introspective Awareness in Large Language Models | 10 min | AI Research | Jack Lindsey, Anthropics
Researchers test whether models can ‘look inward’ by injecting activation patterns and asking them to report on their internal state. Some models notice the injected concept, recall prior internal states and distinguish their own outputs from artificial pre‑fills, suggesting a limited form of introspective awareness. However, the ability is highly unreliable and context‑dependent, and the experiments may not correspond to human‑like self‑awareness.
Multi‑Agent SQL Assistant, Part 2: Building a RAG Manager | 21 min | Data Engineering & ML | Alle Sravani, Towards Data Science
Passing an entire database schema to an LLM can blow up token usage. This article introduces a Retrieval‑Augmented Generation (RAG) manager that selects relevant tables and columns using four strategies: a baseline with no RAG, Keyword RAG using domain‑specific keywords, FAISS RAG using vector similarity and Chroma RAG using a persistent vector store. Sravani implements a BaseRAG abstract class to unify these strategies and compares their pros and cons in terms of token savings and accuracy.
Expected Value Analysis in AI Product Management | 18 min | AI Product Management | Chinmay Kakatkar, Towards Data Science
Decision‑making under uncertainty is hard, especially for AI teams dealing with probabilistic algorithms, scarce data and hype‑driven expectations. This deep dive introduces expected value as a framework to evaluate strategic decisions. Using dice and roulette examples, the article shows how expected value can guide product managers toward optimal choices and presents case studies on fraud detection, user‑acquisition campaigns and retention.
Perplexity at Work: A Guide to Getting More Done | ~30 min | Productivity & AI | Perplexity AI
This long-form guide reframes AI as a natural extension of three stages of work: blocking distractions, scaling yourself and delivering measurable results. It advocates reclaiming focus by delegating repetitive tasks, using AI to augment research and creation, and channeling that bandwidth into outcomes. The guide showcases Perplexity’s unified AI platform—Comet, Labs, Research, Spaces and an Email Assistant—which keeps research, notes and workflows in one place.
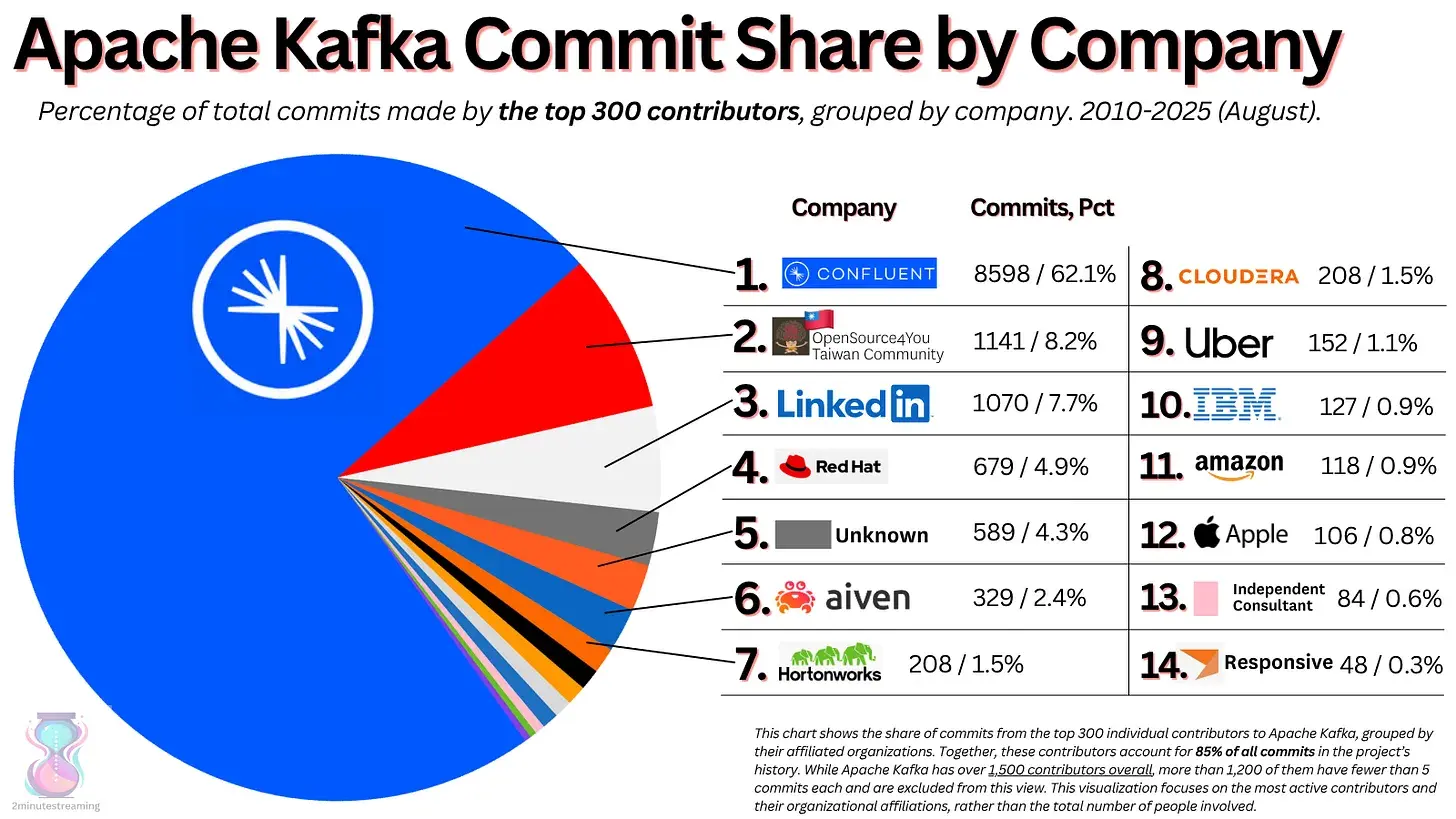
Event Streaming is Topping Out | 14 min | Streaming & Business | Stanislav Kozlovski
Kozlovski argues that the event‑streaming industry is over‑saturated and headed toward consolidation. With too many companies chasing a limited market, he notes that Confluent’s growth is decelerating—its cloud product’s growth rate has dropped to 24%, contributing to a total revenue growth of around 19%. He lists numerous competitors entering the Kafka ecosystem and explains how new architectures like diskless Kafka and falling prices are squeezing margins, suggesting a wave of mergers or pivots.
DATA TUBE
Fine‑Tuned Models Are Getting Out of Hand | 37 min | MLOps Community
Jaipal Singh Goud and Demetrios Brinkmann discuss how fine‑tuned models and retrieval‑augmented generation (RAG) systems power personalised AI agents. They explore use cases for small language models versus RAG, when to fine‑tune versus rely on RAG, and how fine‑tuning can help agents ask the right questions. The summary asks: How do fine‑tuned models and RAG systems enable agents that learn, collaborate and transform enterprise
Why Are These AI Agents Continuously Failing? – Stress Testing and Diagnosing MCP‑Enabled Agents | 19 min | Duke University & Zoom Video
Based on the LiveMCP‑101 benchmark, this talk stresses AI agents that use the Model Context Protocol (MCP) to orchestrate multiple tools. The benchmark contains 101 real‑world, multi‑step queries requiring coordinated tool use; experiments show that current LLM agents succeed on fewer than 60 % of tasks, revealing failures in tool planning, orchestration and token efficiency. The authors diagnose distinct failure modes and provide insights for building more robust agentic systems.
TOOL
Kubetorch aims to bridge the gap between Kubernetes and open‑source ML frameworks with a zero‑cost abstraction for infrastructure. The post explains that current ML frameworks lack fault tolerance and scalability; Kubetorch’s open‑source core provides a portable interface across OSS frameworks and Kubernetes, with a serverless option and an interactive CLI and Python API. The commercial platform remains separate, emphasising community‑driven development.
Anthropic introduces ‘Agent Skills’, packages of instructions, scripts and resources that enhance Claude’s performance on specialised tasks (e.g., spreadsheets or brand guidelines). Skills are composable, portable and efficient; they automatically load when relevant and can include executable code. They work across Claude Code, the Claude API and consumer apps. A skill‑creator wizard and management endpoints let developers build and deploy custom skills while maintaining security and compliance.
CONFS, EVENTS, WEBINARS AND MEETUPS
Agents in Production 2025 – MLOps × Prosus | November 18, 3PM CET Online
The sixth annual virtual conference on agentic AI in production features 30+ talks from leading practitioners at Meta, OpenAI, NVIDIA and more. Expect a high‑energy format with skits, live music and networking; learn about real‑world agent deployments, lessons learned and deep technical dives.
Operating Model Under Pressure: How Zilveren Kruis Is Redesigning Its Data & AI Model | 50 min | December 4, 4 PM CET Online| Data&AI Strategy | Steven Nooijen (Xebia) and Stefan Bakker (Zilveren Kruis).
The Netherlands’ largest health insurer is reimagining its data and AI operating model to handle generative AI, self‑service analytics and plug‑and‑play tools. The webinar covers empowering teams with self‑service capabilities, deploying AI productivity suites, establishing new ways of working between business, data and IT, and redefining data roles and governance
The Data & AI Warsaw Tech Summit (April 21–22 2026) is extending its call for presentations until Nov 17. With over 600 expected participants and dozens of speakers, this is a chance to share your data or AI story with a broad audience. The selection committee includes experts from top data‑driven companies.
PINNACLE PICKS
Your last week top picks:
Beyond RAG: AI agents with a real‑time context | 9 min | AI Agents | Marek Maj
This post argues that retrieval‑augmented chatbots suffer from “contextual blindness” when relying on stale batch data. A new architecture combines Apache Kafka, Flink and LangGraph with pgvector to stream events and maintain real‑time context so agents can answer with up‑to‑the‑moment business information
How and Why Netflix Built a Real‑Time Distributed Graph – Part 1 | 10 min | Streaming | Adrian Taruc & James Dalton
A Real‑Time Distributed Graph (RDG) powers Netflix personalisation by modelling entities and interactions as connected nodes. Kafka ingests data and Apache Flink filters, enriches and deduplicates millions of events per second, keeping the graph continuously up to date for instant cross‑domain insights.
_____________________
This post argues that retrieval‑augmented chatbots suffer from “contextual blindness” when relying on stale batch data. A new architecture combines Apache Kafka, Flink and LangGraph with pgvector to stream events and maintain real‑time context so agents can answer with up‑to‑the‑moment business information
How and Why Netflix Built a Real‑Time Distributed Graph – Part 1 | 10 min | Streaming | Adrian Taruc & James Dalton
A Real‑Time Distributed Graph (RDG) powers Netflix personalisation by modelling entities and interactions as connected nodes. Kafka ingests data and Apache Flink filters, enriches and deduplicates millions of events per second, keeping the graph continuously up to date for instant cross‑domain insights.
_____________________
Have any interesting content to share in the DATA Pill newsletter?
