
ARTICLES
Evolving Recommendations: A Personalized User-Based Ranking Model | 7 min | ML | Yingji Pan, Bing Zhou and Yuri M. Brovman | eBay Tech Blog
Ebay's team story on how they improved their user-based ranking model by employing a deep and wide neural network to enhance predictions for clicks and purchases. Following successful A/B tests conducted on eBay's View Item Page and Homepage, they are exploring additional improvements, including integrating more engagement labels and upgrading the loss function to boost the model's overall performance.
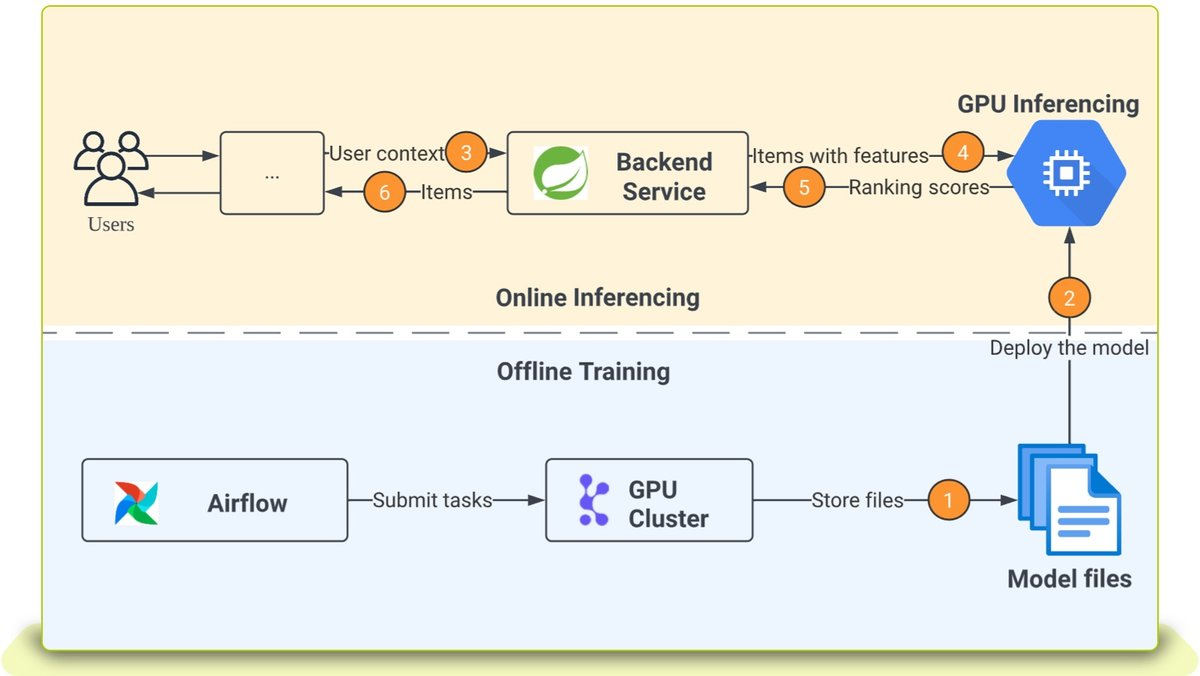
How LinkedIn Is Using Embeddings to Up Its Match Game for Job Seekers | 7 min | Data Science | Jacob Mannix | Linkedin Engineering
This post discusses Linkedin’s team approach to developing software infrastructure for scaling up the incorporation of embeddings. They will also explain how they leverage this technology to enhance the efficiency and effectiveness of matching job seekers with companies.
Exploring Coalesce.io — an alternative to dbt, built on Snowflake | 8 min | Data Engineering | Hugo Lu | Personal Blog
Let's find out more about Coalesce.io. It's built exclusively for Snowflake, emphasizing data modeling and transformation with version control and environment management features. Its UI is clean but may require some setup effort. While it lacks an in-built scheduler, it enforces best practices. Its performance remains to be tested, and pricing details must be compared thoroughly with tools like dbt.
TUTORIALS
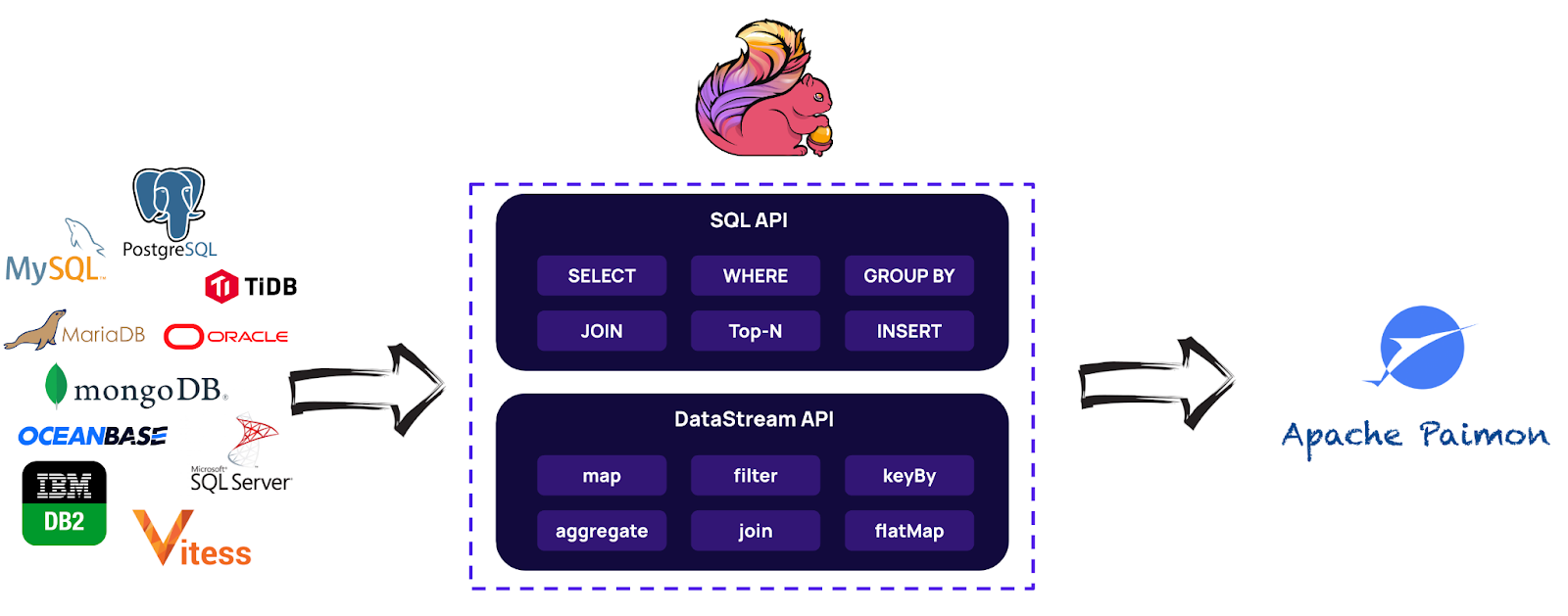
Apache Paimon: the Streaming Lakehouse | 8 min | Data Streaming | Giannis Polyzos | Ververica Blog
Apache Paimon, a streaming storage layer for Apache Flink, supports real-time data ingestion, low-latency queries and efficient data management in the Lakehouse paradigm. It leverages Dynamic Tables, Snapshots and Change Data Capture for high-performance streaming data storage, serving various use cases and gaining traction in large-scale production environments to bolster the Apache Flink ecosystem.
Kedro Dynamic Pipelines | 14 min | MLOps | Marcin Zabłocki | GetInData | Part of Xebia Blog
This tutorial will guide you through the process of implementing dynamic pipelines in Kedro, while still sticking to the framework’s main concepts and principles.
7 tips for writing better GitLab pipelines | 8 min | DevOps | Jeffrey Zaayman | Xebia Tech Blog
A robust CI/CD pipeline is essential for efficient software delivery in DevOps. This tutorial offers tips to maximize GitLab's pipeline capabilities, whether you're a beginner or an expert, to enhance your GitLab experience.
NEWS
Inference Tables: Simplified Monitoring and Diagnostics for AI models | 4 min | Ahmed Bilal, Steven Chen, Kasey Uhlenhuth, Joshua Hartman and Alkis Polyzotis | AI | Databricks Blog
Databricks introduces Inference Tables, a feature designed to simplify monitoring and diagnostics for AI models. Inference Tables enable continuous capture of input and predictions, facilitating easy monitoring, debuggingnand optimization of AI models within the Lakehouse platform, enhancing performance and business outcomes.
TOOLS
Ray on Vertex AI | 4 min | ML | Google Cloud Blog
Ray is an open-source framework for scaling AI and Python applications, providing infrastructure for distributed computing and parallel processing in ML workflows. It seamlessly integrates with Vertex AI, allowing users to leverage their existing Ray code for efficient scaling and enhanced integration with Google Cloud services.
RisingWave | 4 min | SQL
RisingWave is a stream processing platform that utilizes SQL to enhance data analysis, offering improved insights on real-time data.
PODCASTS
When Will AI Hit the Enterprise? | 26 min | AI | Ben Horowitz and Ali Ghodsi | a16z Podcast
This episode delves further into the insights shared at a16z's recent AI Revolution event. Join us as we bring you direct insights from Ben Horowitz, co-founder of a16z, and Ali Ghodsi, co-founder and CEO of Databricks. They will address pressing questions related to AI in the business world. Additionally, they will share their viewpoints on the significance of open-source technologies, the validity of benchmarks and the intriguing phenomenon of universities eagerly participating in the AI revolution they initiated decades ago.
LLMs for Evil | 26 min | LLM | Maximilian Mozes | Data Skeptic Podcast
Maximilian highlighted the dark potential of NLPs, including generating phishing emails, malicious code and fake news at scale. He then shared prevention measures, AI safety, red teaming and challenges in improving LLM harmlessness. Additionally, he touched on data poisoning, jailbreaking and countermeasures.
CONFS EVENTS AND MEETUPS
GoDataFest | Amsterdam | 24-26th October 2023
A multitude of sessions focused on various data & AI technologies and platforms. From fireside chats and presentations to ask-me-anything sessions and/or workshops, each session hosted by seasoned experts.
You can expect insights, developments and tutorials about the latest and greatest data technology. Topics include modern data platforms, analytics engineering, data democratization, AI, MLOps, pipeline orchestration and much, much more.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
