
ARTICLES
What is the best tool: Apache Airflow, Azure Data Factory, or Databricks Workflows? | 7 min | Data Engineering | Pedro Pagano | Indicium Engineering Blog
In a recent data project, Pedro suggested Apache Airflow, but due to past experiences, the company chose a managed platform, leading to a project on Azure Cloud with Databricks. He compared Azure Data Factory and Databricks Workflows with Airflow to determine the best orchestrator/scheduler.
Retrieving information from SQL databases with the help of LLMs | 6 min | LLM | Piotr Chaberski | GetInData | Part of Xebia Blog
LLM has recently gained significant traction, inspiring innovative use cases and demos. As the hype evolves into practical applications, information retrieval emerges as a focal point, prompting considerations about deployment strategies, data privacy, and accessing information beyond LLMs' parameters.
Elevating Your Data Platform: The Strategic Role of Data Staging Area and how it fits Data Lakehouse paradigm | 14 min | Data Engineering | Szymon Żaczek | Level Up Coding
Optimize data management with a Data Staging Area in your Lakehouse architecture for enhanced security, efficiency, and scalability.
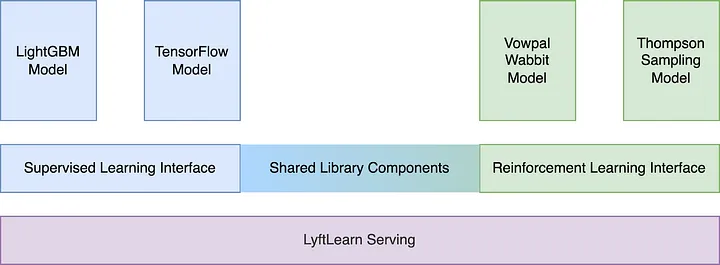
Lyft’s Reinforcement Learning Platform | 16 min | ML | Jonas Timmermann | Lyft Engineering Blog
Learn how the Lyft team extended their existing machine learning ecosystem to support Reinforcement Learning models, develop models using Off-Policy Evaluation, and the lessons learned along the way.
SKILL LAKE
Big Data Technology Warsaw - Workshops | Warsaw, On-site | 9th April
- Building Generative AI Based Applications With LLMs and Data Augmentation Architectures
Join a one-day workshop on Generative AI and large language models. This event aims to provide participants in-depth knowledge of the latest advancements in natural language processing, computer vision, and machine learning techniques for Gen AI.
- Data Streaming: Analyze Your Data in Real-Time With Flink
In this one day workshop you will learn how to build streaming analytics apps that deliver instant results in a continuous manner on data-intensive streams. You will discover how to configure streaming pipelines, transformations, aggregations or triggers using SQL and Python in an user-friendly development environment using open source tools of Apache Flink, Apache Kafka and Getindata OSS projects.
- Advanced analytics engineering with Snowflake and dbt
Learn to build and optimize data pipelines using dbt and Snowflake in a one-day workshop. Discover how to enhance performance, quality, and cost-efficiency through materialization techniques, version control, testing, monitoring, and scheduling. Solve common data transformation challenges with modern tools, using hands-on exercises in a public cloud (GCP or AWS).
REMEMBER! Use the DataPill200 code to get the 200 PLN discount.
TUTORIALS
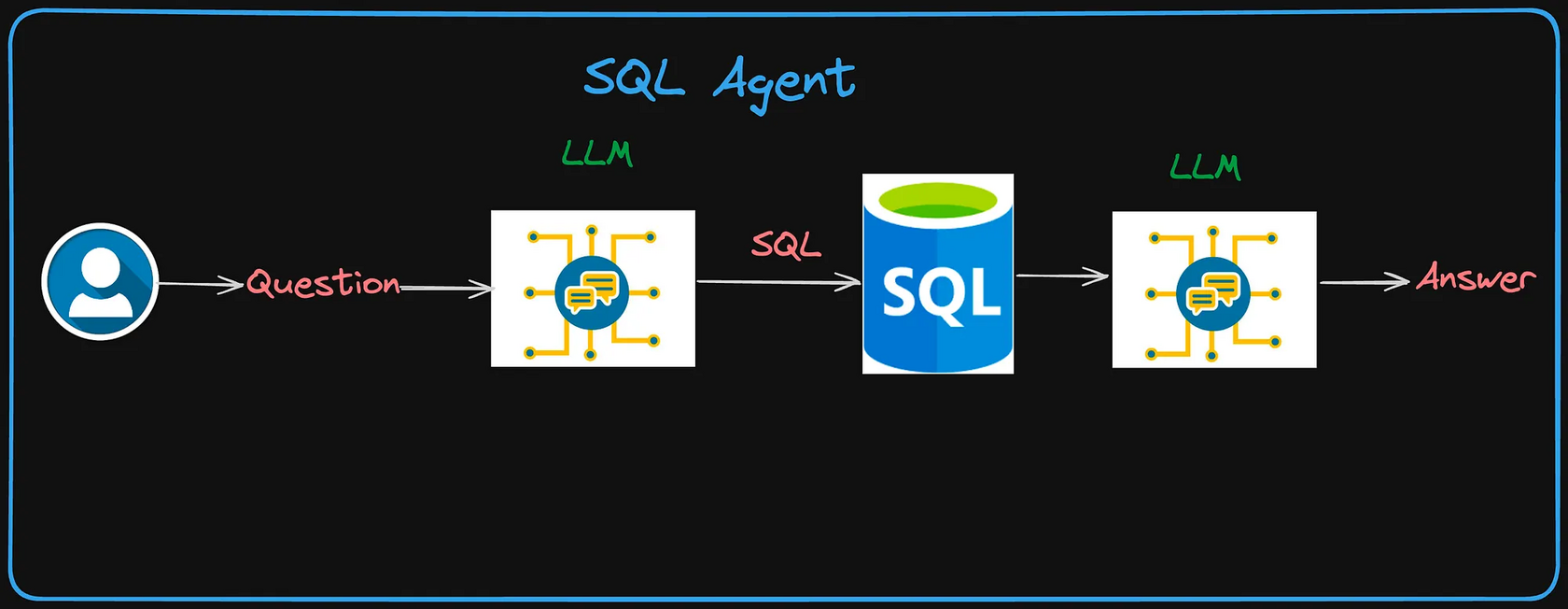
LLMs Meet SQL: Revolutionizing Data Querying with Natural Language Processing | 56 min | LLM | Senthil E | Level Up Coding
This article explores how powerful models simplify tasks by writing database queries from questions, building knowledgeable chatbots, and creating custom dashboards for preferred information. It will also uncover the potential of combining Large Language Models (LLMs) with structured data to unlock new possibilities and streamline data interaction.
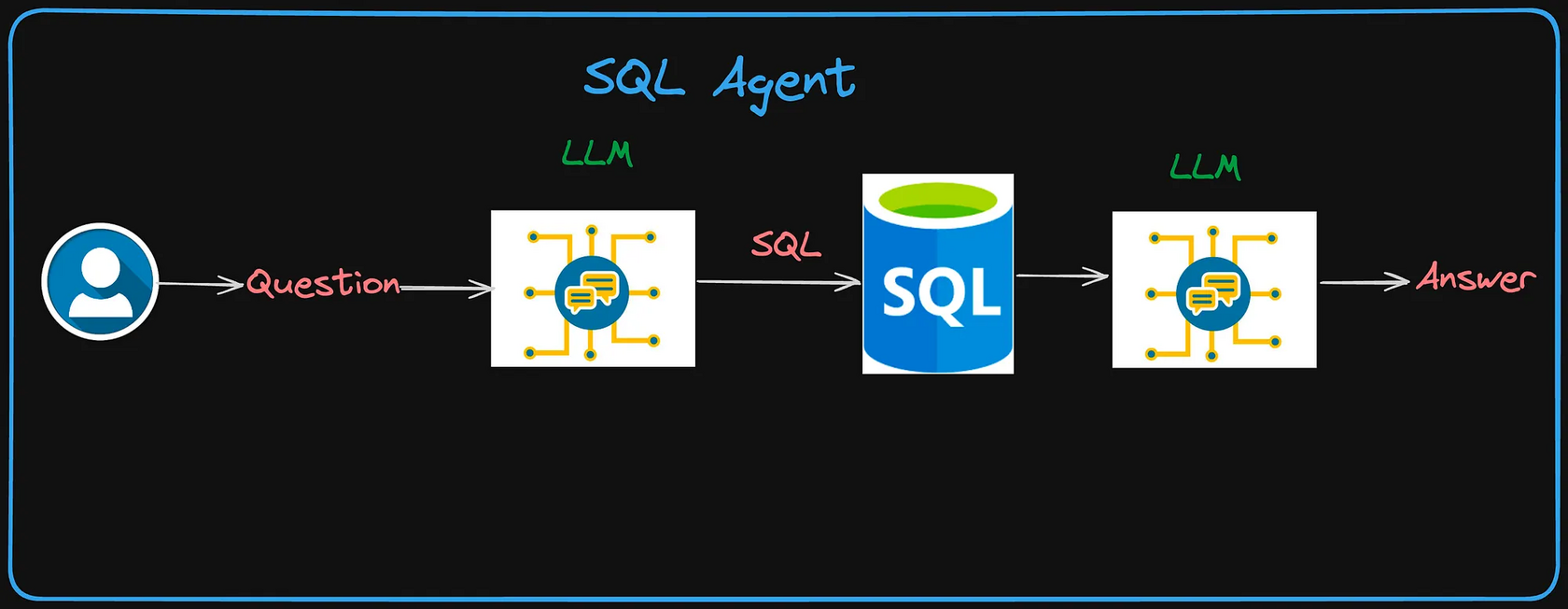
We built a new SQL Engine on Arrow and DataFusion | 14 min | Data Streaming | Micah Wylde | Arroyo Blog
Arroyo is coming up on its one-year anniversary as an open-source project, and we've got something big planned. Our next release, 0.10, will feature an entirely new SQL engine built around Apache Arrow and the DataFusion SQL toolkit. This post will detail Arroyo's current implementation and why it's changing.
NEWS
Announcing the Release of Apache Flink 1.19 | 7 h | Data Streaming | Lincoln Lee
The Apache Flink PMC is pleased to announce the release of Apache Flink 1.19.0. As usual, we are looking at a packed release with a wide variety of improvements and new features. Overall, 162 people contributed to this release completing 33 FLIPs and 600+ issues.
Confluent Cloud for Apache Flink Is Now Generally Available | 8 min | Data Streaming | Jean-Sébastien Brunner, Hasan Jilani | Confluent Blog
Confluent has launched Confluent Cloud for Apache Flink, which is available on all major cloud platforms. This integration offers a unified, enterprise-grade solution for real-time data processing with Apache Kafka® and Flink. The blog details the unique features of this fully managed service and its readiness for mission-critical use cases at scale.
PODCAST
Open-Source LLM Libraries and Techniques | 1 h 48 min | LLM | Jon Krohn, Dr. Sebastian Raschka | Super Data Science: ML & AI Podcast
Jon Krohn sits down with Sebastian Raschka to discuss his latest book, Machine Learning Q and AI, the open-source libraries developed by Lightning AI, how to exploit the greatest opportunities for LLM development, and what’s on the horizon for LLMs.
CONFS EVENTS AND MEETUPS
Machine Learning Prague 2024 | Prague | 22-24th April 2024
World class expertise and practical content packed in 3 days. You can look forward to an excellent lineup of 40 international experts in ML and AI business and academic applications at ML Prague 2024. They will present advanced practical talks, hands-on workshops and other forms of interactive content to you.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
