ARTICLES
Overclocking dbt: Discord's Custom Solution in Processing Petabytes of Data| 19 min | Data Engineering | Chris Dong | Discord Engineering Blog
Discover how Discord scaled dbt to manage petabytes of data and a large developer team. Learn about their custom solutions to overcome challenges like slow compile times and inefficient backfills.
10 tips for migrating from SAS Viya to Snowflake + dbt | 3 min | Analytics Engineering | Lasse Benninga | Xebia Blog
Get practical advice on transitioning from SAS Viya to Snowflake and dbt. This guide covers handling true deletes, SAS-specific logic, and implementing robust testing practices.

Introducing Docker Model Runner: A Better Way to Build and Run GenAI Models Locally | 3 min | AI | Deanna Sparks | Docker Blog
Explore Docker's new tool that simplifies running and testing AI models locally. It standardizes model packaging and supports GPU acceleration for efficient local development.
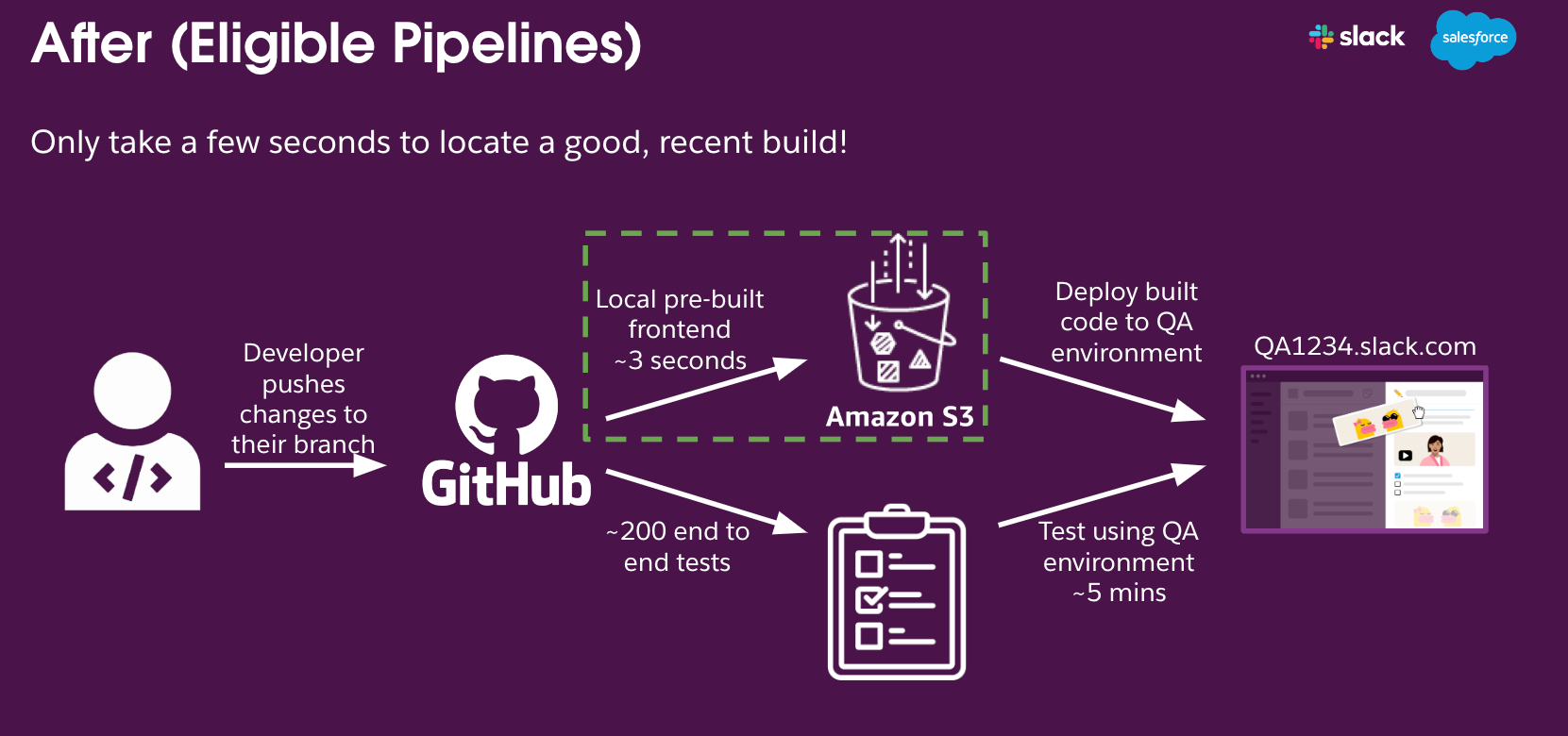
Optimizing Our E2E Pipeline | 8 min | DevOps | Dan Carton | Slack Engineering Blog
Learn how Slack's DevXP team reduced frontend build times in their CI/CD pipeline by 80% using conditional builds and prebuilt asset caching.
TUTORIALS
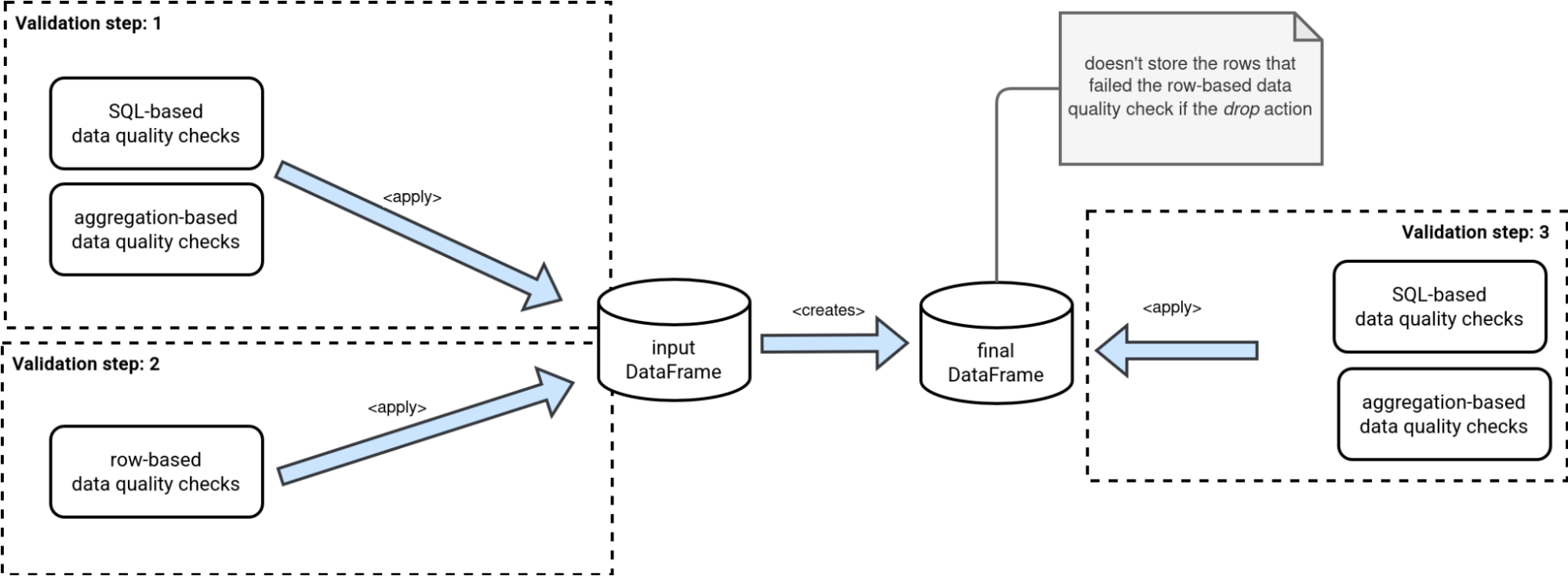
Data quality on Databricks - Spark Expectations | 5 min | Data Quality | Bartosz Konieczny | Waiting for Code Blog
Understand how to enforce data quality in Apache Spark using Spark Expectations. This tutorial covers defining and applying various validation rules.
GenAI + dbt = dbt-sqlx: The Easiest Way to Switch SQL Dialects | 4 min | Gen AI | Nikhil Suthar | Data Engineer Things
Discover dbt-sqlx, a GenAI-powered CLI tool that translates dbt models across SQL dialects, simplifying warehouse migrations and reducing manual rewrites.
TOOL
HyperDX | Data Engineering
HyperDX centralizes logs, metrics, traces, exceptions, and session replays, helping engineers quickly diagnose production issues. It's an open-source alternative to Datadog and New Relic.
DATA LIBRARY
polars-bio – fast, scalable and out-of-core operations on large genomic interval datasets | 15 min | Data Engineering | Marek Wiewiórka, Pavel Khamutou, Marek Zbysiński, Tomasz Gambin
Explore polars-bio, a high-performance Python library for analyzing large genomic datasets. Built on Apache Arrow and DataFusion, it offers significant speed and memory efficiency improvements.
PODCAST
Prompts as Functions: The BAML Revolution in AI Engineering | AI | 38 min | Ben Lorica, David Hughes | The Data Exchange Podcast
Learn about BAML, a domain-specific language that transforms prompts into structured functions, enabling more deterministic and maintainable AI applications.
CONFS, EVENTS AND MEETUPS
GoDataFest | Amsterdam | May 26-28th
Join GoDataFest 2025 in Amsterdam for three days of expert-led sessions, hands-on workshops, and networking focused on the latest in data and AI technology. Hosted by Xebia, this in-person event covers topics like modern data platforms, analytics engineering, and MLOps.
PINNACLE PICKS
Your last week top picks:
Announcing Airbyte Embedded | 3 min | AI | Teo Gonzalez | Airbyte Blog
Airbyte now lets you embed data pipelines directly into your AI app. A must-have for building context-rich assistants or copilots.
MarkItDown | LLM
A simple Python tool that turns docs into Markdown, preserving structure for LLM consumption. Clean, readable, and tailor-made for pipelines.
The Top 7 MCP-Supported AI Frameworks | 19 min | AI | Amos Gyamfi | Personal Blog
A hands-on guide to frameworks like LangChain, Chainlit & Mastra that make integrating tools into LLM agents a breeze using the Model Context Protocol (MCP).
________________________
Have any interesting content to share in the DATA Pill newsletter?