
ARTICLES
Taming the tail utilization of ads inference at Meta scale | 6 min | ML | Rohith Menon, Bikash Sharma, Deepak Tiwari | Meta Engineering Blog
This blog explores how Meta optimized tail utilization to enhance the performance and reliability of its ads inference service. Through innovative load-balancing techniques and infrastructure improvements, Meta achieved a 35% increase in work output, a two-thirds reduction in timeout errors, and a 50% decrease in p99 latency.
The majesty of Apache Flink and Paimon | 12 min | Data Engineering | Giannis Polyzos | Personal Blog
This blog post explores Paimon's innovative approach to integrating with Flink, offering real-time data streaming, efficient changelog handling, and unified storage for batch, OLAP, and streaming data. Learn how Paimon can enhance your data processing capabilities and streamline your analytical solutions with Flink.
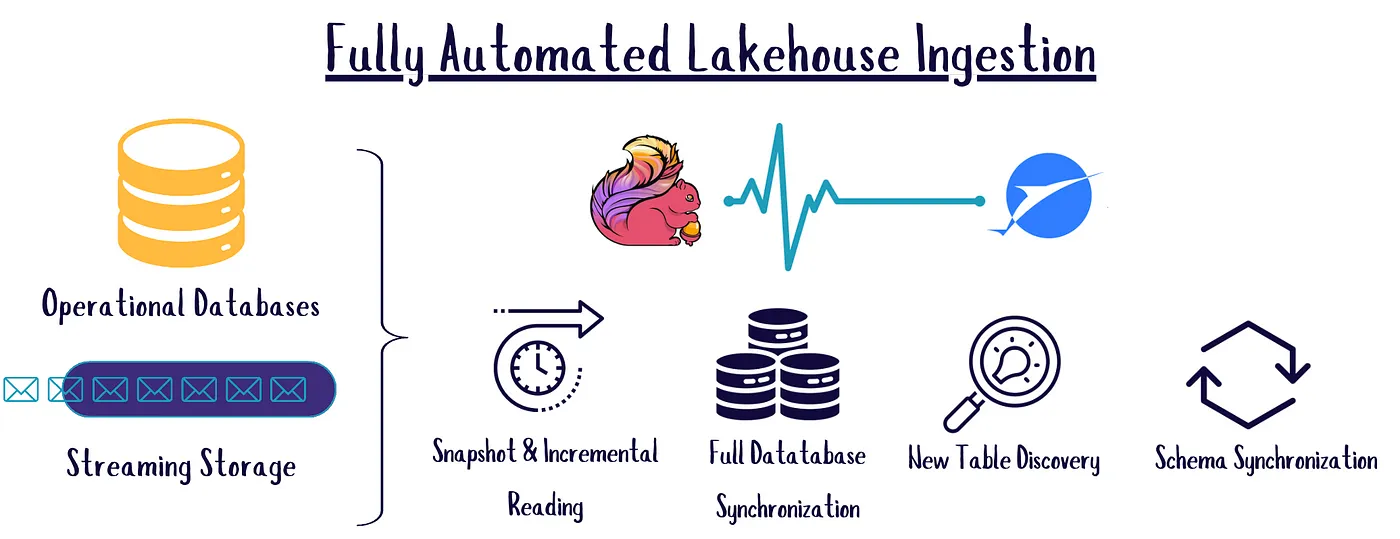
How data observability fits into the different stages in the data pipeline | 9 min | Data Observability | Mikkel Dengsøe | Personal Blog
This article explores the role of data observability tools in ensuring data quality, managing transformations, and delivering reliable analytics, drawing insights from our experience with 1,000 data teams.
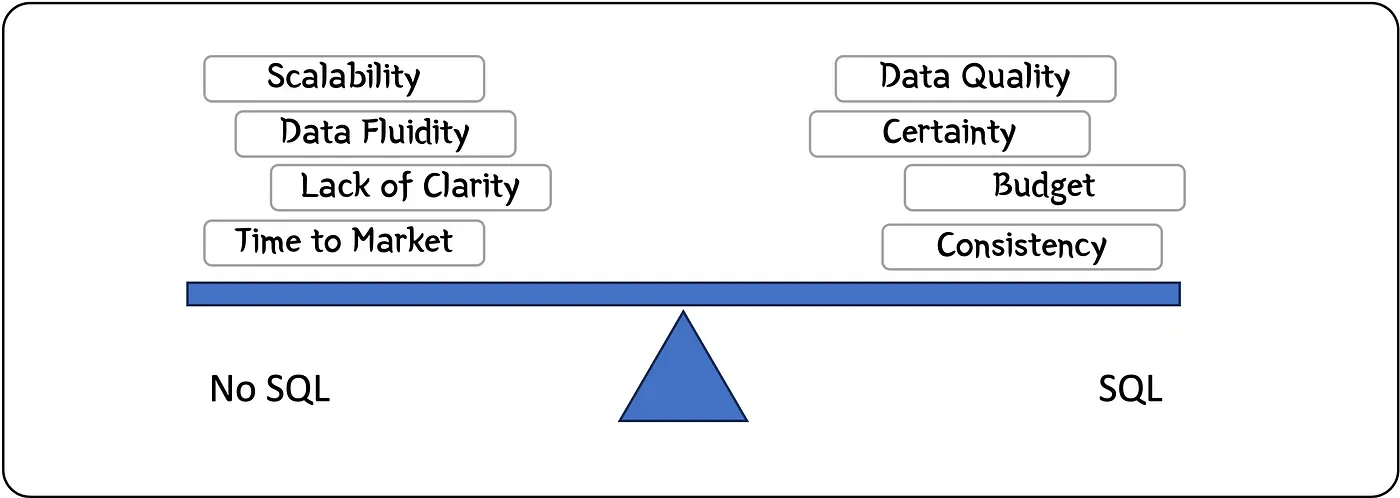
How I choose between SQL and No-SQL solutions | 14 min | Database | Martin Hodges | Personal Blog
In this article, Martin discusses how he would choose between SQL and No-SQL databases for a solution. He explores the roles of structured and unstructured data in this decision and other factors. This decision-making process can be complex.
NEWS
Amazon DataZone introduces OpenLineage-compatible data lineage visualization in preview | 16 min | Data Engineering | Leonardo Gomez, Ron Kyker, Srinivasan Kuppusamy, Priya Tiruthani | AWS blog
AWS introduces OpenLineage-compatible data lineage visualization in Amazon DataZone, enhancing data movement and transformation tracking.
Apache Paimon: Streaming Lakehouse is Coming | 7 min | Data Streaming | Alibaba Cloud blog
This blog post explores race conditions and changelogs in Flink SQL, highlighting potential pitfalls and solutions for ensuring data consistency and reliability. We'll cover changelogs' mechanics, race conditions' impact, and practical mitigation strategies, helping you maximize Flink SQL's potential in streaming applications.
TUTORIAL
Easy automated testing in Databricks | 9 min | Data Engineering | Jimmy Jensen | Personal Blog
Unit and integration testing in Databricks has been challenging, but recent advancements like Databricks Serverless Spark make continuous integration more efficient. This guide provides practical steps to streamline your testing processes and reduce costs.
PODCAST
AI/ML in Kubernetes |1 h 48 min | AI/ML | Hosts: Abdel Sghiouar, Kaslin Fields; Guests: Maciej Szulik, Clayton Coleman, Dawn Chen | Kubernetes Podcast from Google
Listen to a talk with three Kubernetes leaders about its evolution and current efforts to support AI/ML workloads in open-source Kubernetes.
DATA TUBE
Data Science meets engineering - the story of the MLOps platform that unlocks your data science team | 36 min | MLOps | Michał Bryś, Marcin Zabłocki | Data Science Summit
Learn how to create a production-grade MLOps platform using Kedro, MLflow, and Terraform, enhancing your team's productivity.
CONFS EVENTS AND MEETUPS
Introduction to Machine Learning with Snowpark ML | Online | 16th July
Join a hands-on lab to explore Snowflake's end-to-end ML capabilities, from feature engineering to model deployment.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
