
ARTICLES
5 Best Data Observability Platforms | 7 min | Data Observability | Shawn Fergus | Shippyyard Blog
The pros and cons of the 5 best Data Observability Platforms. In this article, Shawn compares Datadog, Splunk, and what else? Check it out.
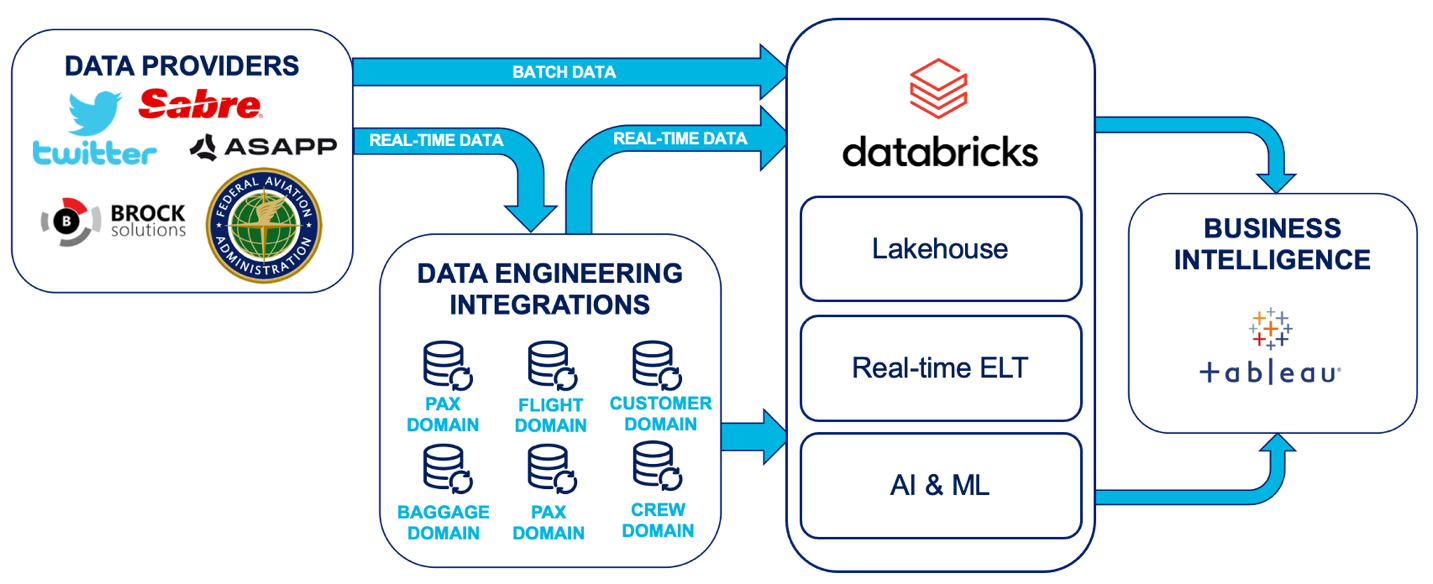
Accelerating Innovation at JetBlue Using Databricks | 8 min | DataOps | Sai Ravuru and Yared Gudeta | Databricks Blog
How JetBlue utilizes Azure, Databricks, and generative AI for customer experience. Shifting to Databricks Lakehouse architecture improves scalability and cost efficiency, while their BlueSky AI system boosts operational efficiency and satisfaction.
Data engineering at Meta: High-Level Overview of the internal tech stack | 12 min | Data Engineering | Alex M. | Meta Engineering Blog
This article provides an overview of the internal tech stack that we use on a daily basis as data engineers at Meta. The idea is to shed some light on the work we do, and how the tools and frameworks contribute to making our day-to-day data engineering work more efficiently, and to share some of the design decisions and technical tradeoffs that we made along the way.
To dbt or not to dbt | 10 min | Data Science | Pragun Bhutani | intercom-rad Blog
Delve into data management challenges, including SQL complexity, and present Intercom's use of dbt for data transformation. It highlights advantages like organized code and staging models, but acknowledges challenges like a learning curve and boilerplate code.
TUTORIALS
Deploying efficient Kedro pipelines on GCP Composer / Airflow with node grouping & MLflow | 7 min | Data Engineering | Artur Dobrogowski | GetInData | Part of Xebia Blog
Have you ever wondered if it’s possible to use Kedro and Airflow together? Dive into the step-by step tutorial on how to deploy Kedro pipelines on GCP Composer and Airflow.
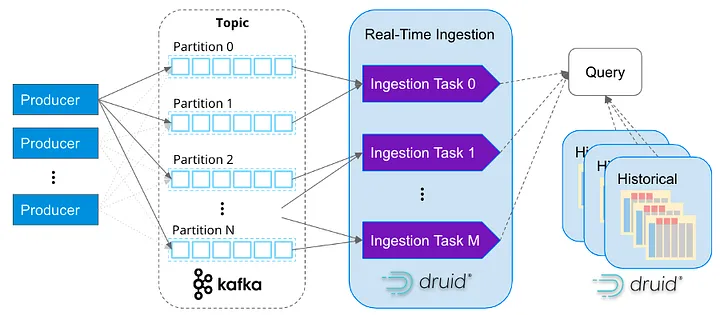
Building a Real-Time Data Architecture with Apache Kafka, Flink, and Druid | 10 min | Real Time Analytics | David Wang | Data Engineering Things
This article explores how, when combined, Apache Kafka, Flink and Druid create a real-time data architecture that eliminates these waiting states and enables various real-time data applications, including alerting, monitoring, dashboards, analytics and personalized recommendations. These tools provide a purpose-built pipeline for real-time data applications and have been used by major companies like Lyft, Pinterest, Reddit and Paytm to achieve the data freshness, scale and reliability required for real-time use cases.
Setting up the new dbt Semantic Layer and testing with DBeaver | 9 min | Data Analytics | Lucas Ortiz | Xebia Blog
Lucas explores the challenge of ensuring uniform metric calculations across various data consumers. He introduces the Semantic Layer as a solution, bridging raw data and users, simplifying data interpretation and promoting consistency. Let's implement a Semantic Layer together.
NEWS
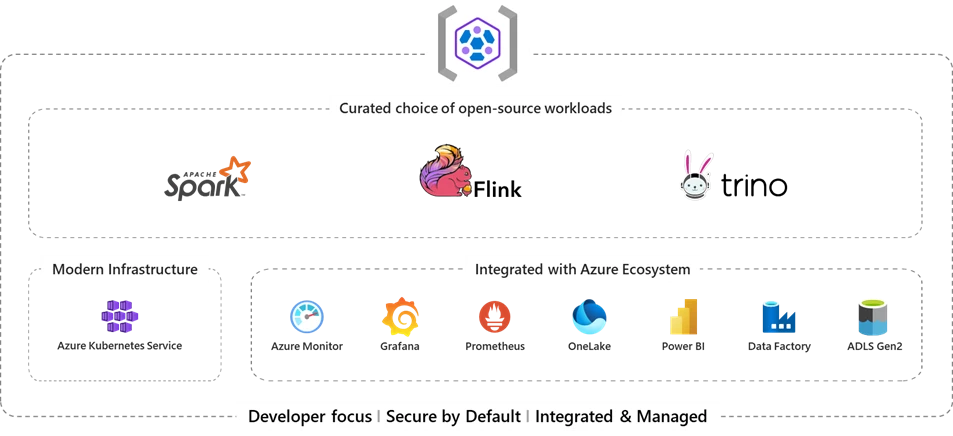
Manage your big data needs with HDInsight on AKS | 4 min | Balaji Sankaran | Cloud | Microsoft Blog
Microsoft is launching a public preview of HDInsight on the Azure Kubernetes Service (AKS), a rearchitected cloud-native big data service with Apache Spark, Apache Flink and Trino workloads. It offers seamless integration with Azure analytics services like Power BI and Azure Data Factory with easy use and robust security. It simplifies library management and resource handling while promoting cost-effective analytics setups.
Docker with Neo4j, LangChain, and Ollama Launches New GenAI Stack for Developers | 4 min | AI | Docker Blog
Docker and partners Neo4j, LangChain and Ollama have released the GenAI Stack, a ready-made solution for quick generative AI app development. Their new product, Docker AI simplifies AI development by offering an out-of-the-box setup for various AI capabilities.
PODCASTS
Versioning and MLOps for Generative AI | 38 min | AI | Ben Lorica and Yucheng Low | The Data Exchange Podcast
In this talk, Yucheng Low addresses the challenges of managing large-scale machine learning assets and the need for version control, emphasizing their platform's collaborative versioning system for diverse data types and open-source integration. The discussion also touches on data deletion challenges and the value of flexibility and openness in data formats.
Do LLMs Make Ethical Choices | 29 min | LLM | Josh Albrecht | Data Skeptic
In this episode, Josh discussed the limitations of current LLMs' decision-making regarding ethics and safety, despite their impressive performance. He explored evaluating LLM ethics, the impact of adversarial inputs and the role of training data, offering insights into the future outlook and critical considerations for LLM adoption.
CONFS EVENTS AND MEETUPS
Introduction to GenAI: How to get the most for your business from the latest AI revolution | Webinar | 9th November 2023
You will find there:
- LLMs - what are they, and how do they work? Also, the new way of interacting with LM models (prompt engineering vs. programming)
- Current LLM landscape - overview of commercial and open-source models
- New possibilities brought by LLMs compared to older NLP approaches and other ML techniques
- GenAI - what is this? What are the main branches and modalities that can be handled?
- Challenges and potential issues with GenAI
- Examples of practical use cases
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
