
ARTICLES
ByteDance Open Sources Its Cloud Native Data Warehouse ByConity | 12 min | Cloud | Vini Jaiswal | ByConity Blog
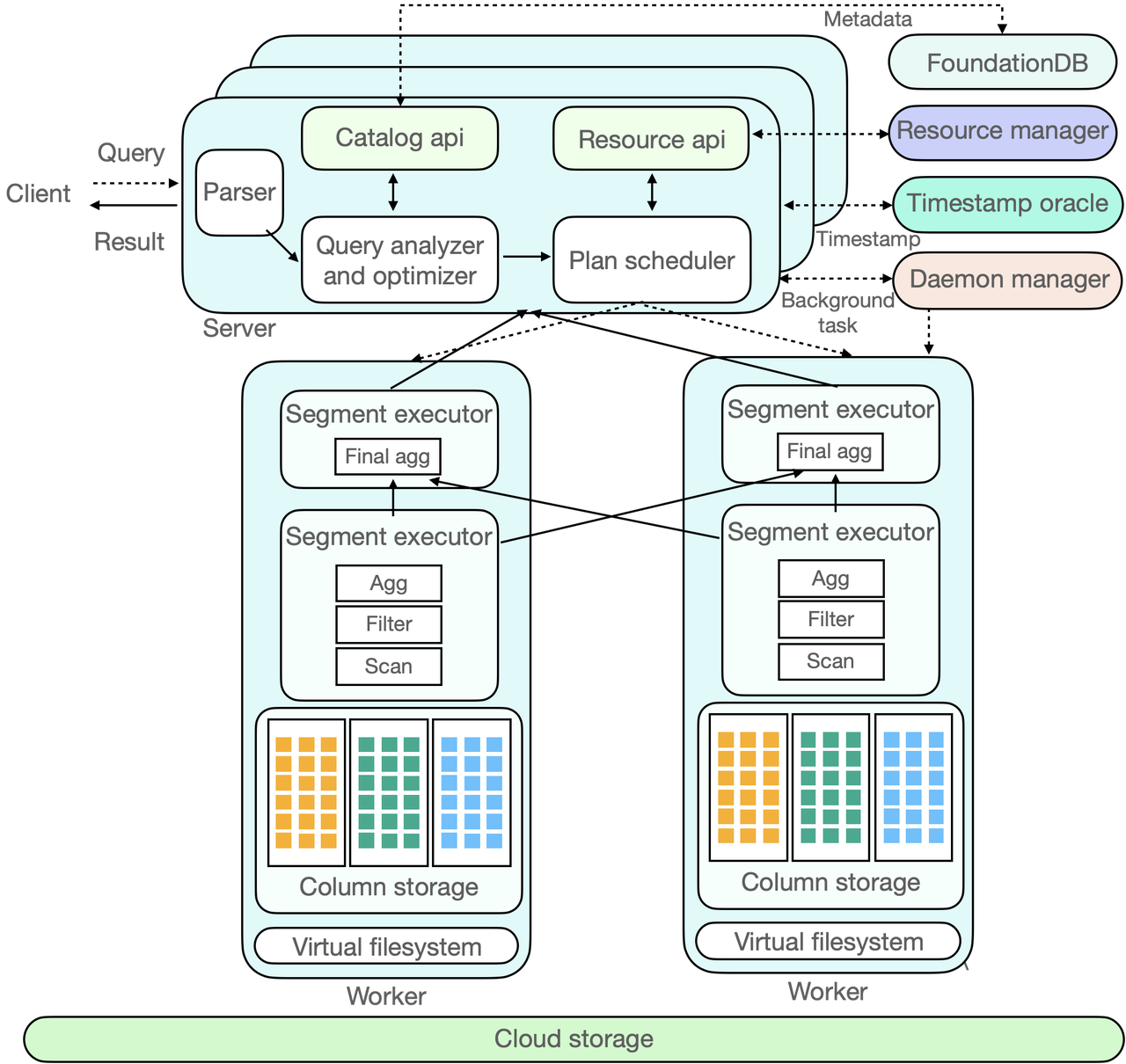
In this text, let’s dive into ByConity, an open-source cloud-native data warehouse developed by ByteDance. ByConity offers a computing-storage separation architecture and essential features such as elastic scalability, tenant resource isolation and strong consistency in data reading and writing. You will explore the history, features, technical architecture and working principle of ByConity, showcasing its advantages over ClickHouse and its components like the query optimizer, query scheduling and virtual file system.
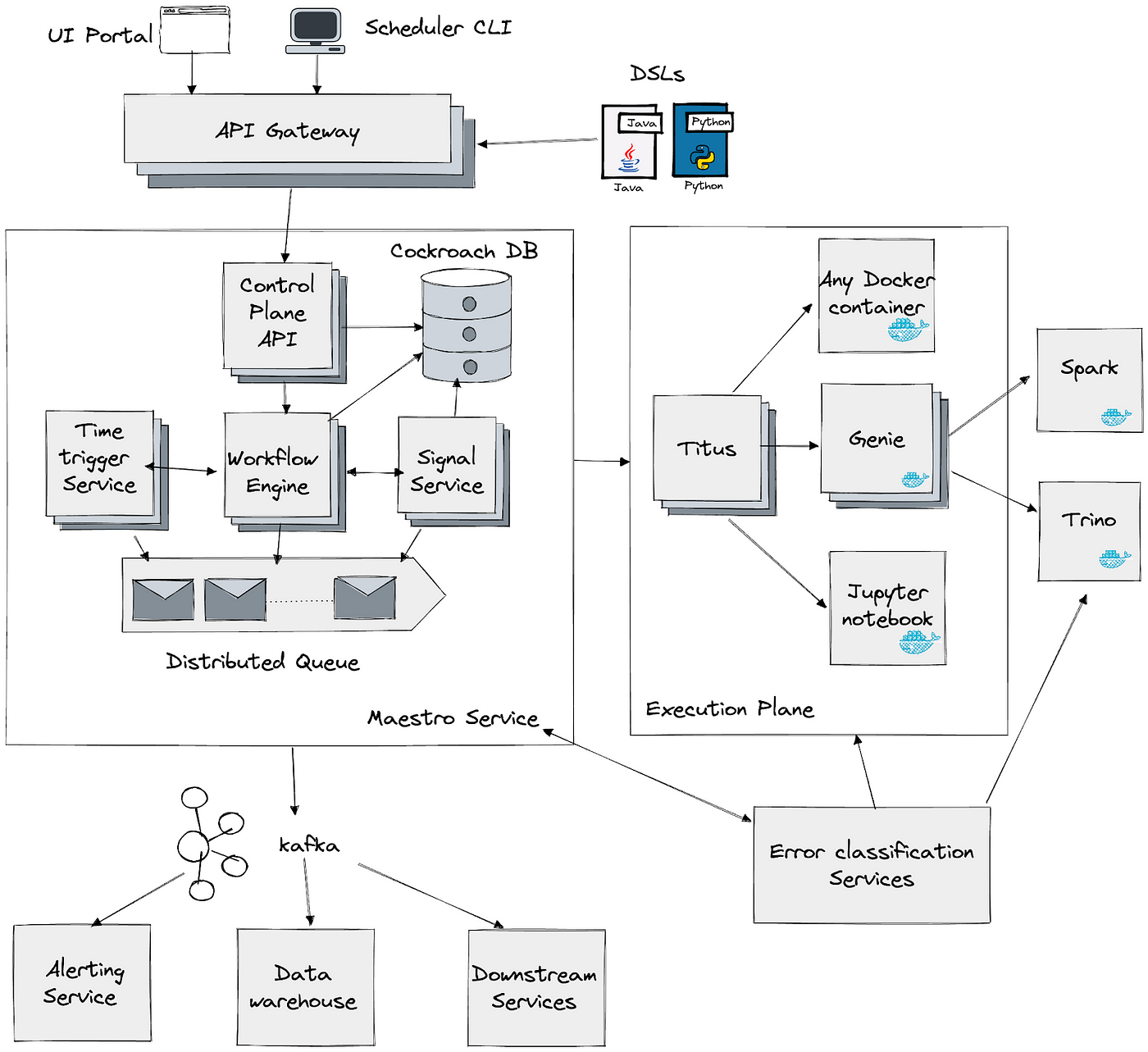
Orchestrating Data/ML Workflows at Scale With Netflix Maestro | 13 min | ML | Jun He, Akash Dwivedi, Natallia Dzenisenka, Snehal Chennuru, Praneeth Yenugutala, Pawan Dixit | Netflix Tech Blog
This article introduces Maestro, a workflow orchestrator developed by Netflix to manage and schedule data and machine learning pipelines at a massive scale. Read about the challenges faced by the previous orchestrator, such as scalability and usability issues, and an explanation about the motivations behind developing Maestro. It provides an overview of Maestro's architecture, including its workflow engine, time-based scheduling service and signal service, emphasizing its scalability, extensibility and usability for various user roles.
GCP Workflows - how can you integrate a lightweight managed orchestrator in Modern Data Stack? GID Modern Data Platform | 10 min | Analytics Engineering | Anita Śledź | GetInData | Part of Xebia Blog
Let’s shed light on the innovative use of GCP workflows to seamlessly integrate a lightweight managed orchestrator into the Modern Data Stack. Discover how this powerful combination enhances data pipeline orchestration, simplifies workflow management and enables the creation of a robust and scalable data platform.
How to Create Valuable Data Tests | 9 min | Data Engineering | Xiaoxu Gao | Towards Data Science Blog
How important are data tests in ensuring data quality? Should we prioritize quality over quantity when creating data tests? Read, find out more and take a look at different dimensions of data quality including external and internal views and practical tips for creating data tests.
TUTORIALS
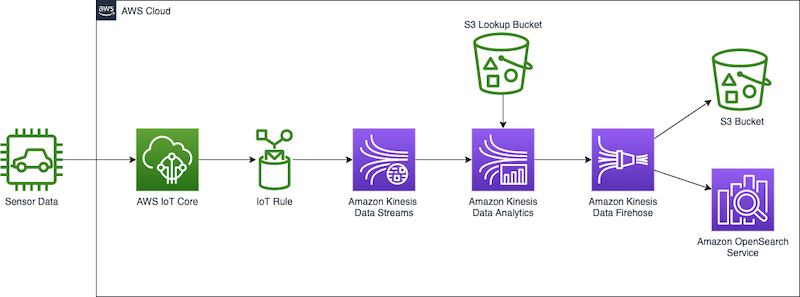
Migrate from Amazon Kinesis Data Analytics for SQL Applications to Amazon Kinesis Data Analytics Studio | 11 min | Data Analytics | Nicholas Tunney | AWS Blog
In this one, you will explore the benefits of migrating from Kinesis Data Analytics for SQL Applications to Amazon Kinesis Data Analytics for Apache Flink, highlighting the advanced streaming capabilities Apache Flink offers. Learn more about Kinesis Data Analytics Studio as a notebook environment for testing and tuning analysis before deploying migrated applications. The tutorial showcases a use case involving real-time analysis of automotive sensor data, using various AWS services, demonstrating the capabilities of Kinesis Data Analytics Studio and the scalability advantages of Kinesis Data Analytics for Apache Flink.
dbt observability 101: How to monitor dbt run and test results | 6 min | Analytics Engineering | Or Avidov | Personal Blog
Dive into implementation options using Jinja variables and a step-by-step guide for implementing dbt observability, by creating a table to store results, implementing a macro to parse results and creating an on-run-end hook to upload the parsed results to the table.
TOOLS
SodaGPT | 3 min | AI
The first generative AI tool for data quality that allows users to express data quality checks without any coding required is already here. It empowers both coders and non-coders to participate in data quality management, bridging the gap between expertise and implementation.
English SDK | 6 min | Data Engineering
The English SDK for Apache Spark is an extremely simple yet powerful tool. It takes English instructions and compiles them into PySpark objects like DataFrames. Its goal is to make Spark more user-friendly and accessible, allowing you to focus your efforts on extracting insights from your data.
Dig into the DATA TUBE section, you will find more there about this tool!
NEWS
Astronomer and Snowflake: Unleash the Power of Snowpark Container Services and Apache Airflow | 3 min | Data Engineering | Juliana O'Donohue, Michael Gregory | Astronomer Blog
Astronomer and Snowflake have teamed up to revolutionize data pipelines. They are partnering up with Snowflake for their Snowpark Container Services launch, bringing code closer to data for the Apache Airflow community. This collaboration introduces new features like Snowpark Operators and a Snowpark Container Services Operator, allowing data teams to orchestrate tasks in any language and workflow.
DATA TUBE
The English SDK for Apache Spark | 29 min | Data Engineering | Gengliang Wang, Allison Wang | Databricks
Let's learn how LLMs simplify SQL query creation, data ingestion, DataFrame transformations, visualization and data insights, leading to faster development and a more understandable code. You will also explore how LLMs enable the creation of user-defined data sources and functions, enhancing adaptability in Apache Spark applications. Join a session filled with practical examples to learn how LLMs drive innovation and efficiency in data science and AI.
PODCAST
Data Journey with Ola Sars (Soundtrack Your Brand) | 29 min | Adam Kawa, Ola Sars | Radio DaTa
Meet Ola Sars, the CEO of Soundtrack Your Brand, a Stockholm-based company providing a cloud-based music streaming platform tailored towards businesses. With licensed commercial music, analytics insights, curated playlists and customizable features, Soundtrack Your Brand enables businesses to shape their brand identity through music.
Topics that were included:
- What Soundtrack Your Brand is, what the product is about, it’s value, who uses it, why and how
- Data-driven use-cases implemented at Soundtrack Your Brand
- Differences between B2B music streaming (e.g. Soundtrack Your Brand) vs. B2C music streaming (e.g. Apple, Spotify)
- If and how data & AI helps in achieving profitability at Soundtrack Your Brand
- Generative AI in the B2B music streaming industry
and much more.
EBay AI, Tech Drive Improvements, Efficiencies | 26 min | AI | Mazen Rawashdeh | Bloomberg Intelligence Tech Disruptors
Listen to a talk with eBay's CTO, Mazen Rawashdeh, who shared his perspective on emerging technology trends and how eBay is embracing the disruption, bringing new customer experiences powered by AI to the marketplace. Mazen tackled subjects like the AI-driven future of work, the value of data insights and the significance of security and privacy in the face of evolving AI, machine learning and blockchain technologies and related regulations.
CONFS EVENTS AND MEETUPS
Data Modeling in SQL | Online Training | 11 AM ET | 11th July
Doing data modeling right makes it easier for data analysts to understand the data they are working with, and helps you maintain data quality. In this live training, you'll learn about data cleaning, shaping and loading techniques and learn about common database schemas for organizing tables for analysis.
Key Takeaways:
- Learn about common database schemas like star and snowflake.
- Learn how to organize your database to make life easier for data analysts.
- Learn about data transformation techniques to fit your data into a schema.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
