
ARTICLES
Ray vs Spark — The Future of Distributed Computing | 11 min | Data Science | Philippe Dagher | Personal Blog
Let’s explore how Ray, designed for low-latency and high-throughput AI/ML workloads, might be a future-proof choice in the ever-changing world of distributed computing, providing valuable insights for decision-makers, researchers and developers.
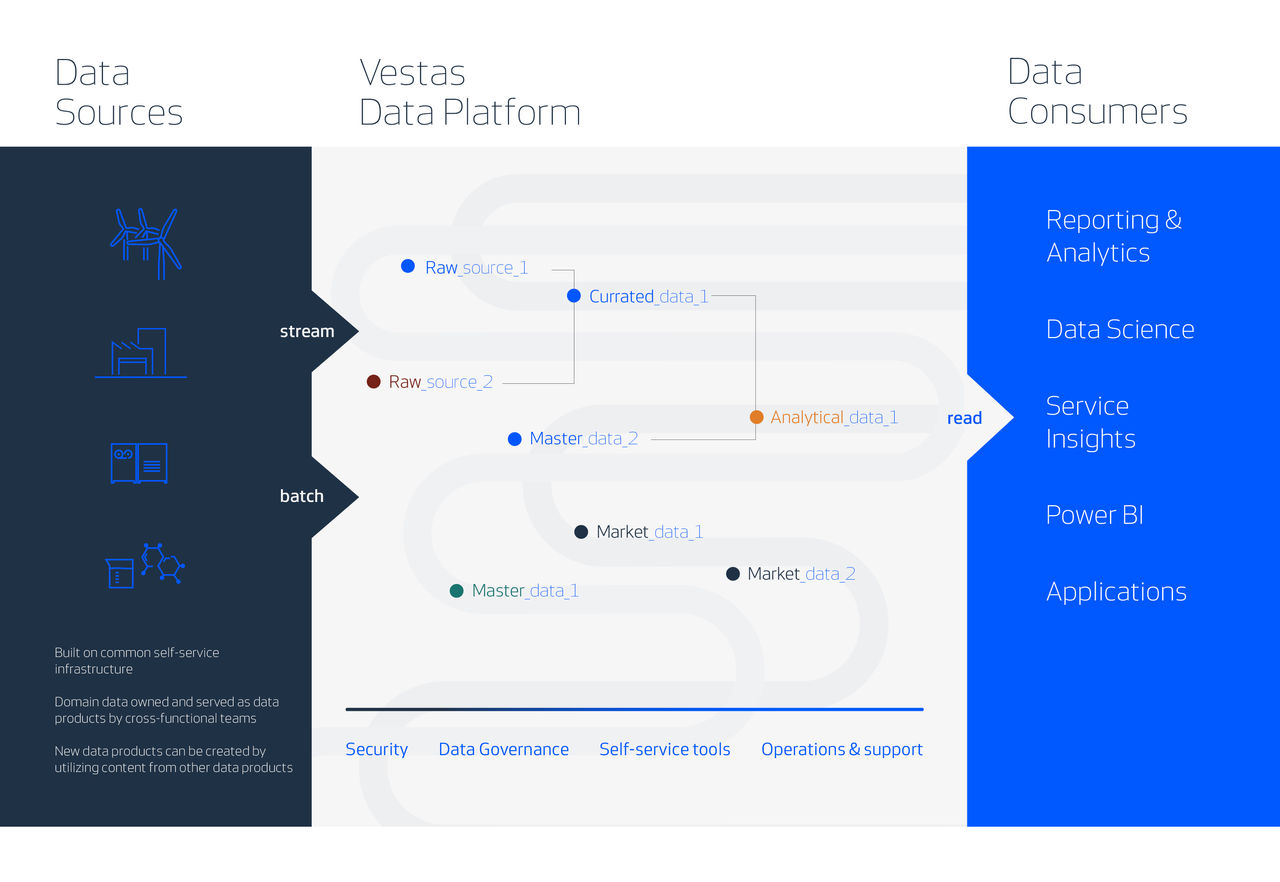
The Vestas Data Platform | 4 min | Data Engineering | Peter Enevoldsen | The Vestas Technology Blog
Vestas has introduced a modular cloud-based Vestas Data Platform to support its sustainable energy solutions, by facilitating digital integration and stream data processing, contributing to the green transition and addressing challenges in the wind-power industry.
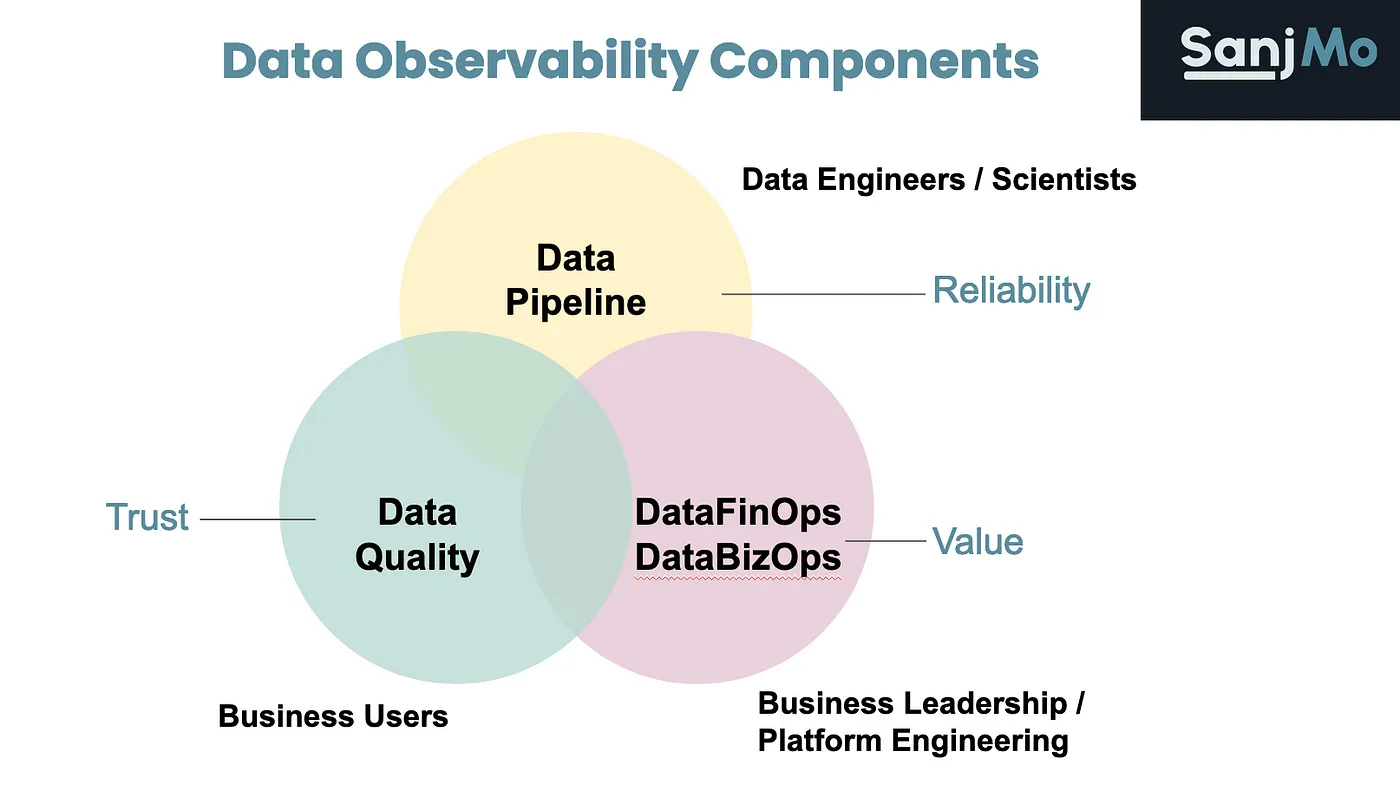
Data Observability’s Newest Frontiers: DataFinOps and DataBizOps | 10 min | Data Observability | Sanjeev Mohan | Personal Blog
This text explains the rising importance of data observability, which ensures data's quality, reliability and now also its DataFinOps and DataBizOps. DataFinOps controls expenses as data complexities increase, while DataBizOps acts as a map to measure productivity and cost reduction.
5 Lessons Learned from Testing Databricks SQL Serverless + DBT | 9 min | Data Engineering | Jeff Chou, Stewart Bryson | Towards Data Science
This blog post touches on a comprehensive analysis of the cost and performance of their serverless SQL warehouse product, employing the widely recognized TPC-DI benchmark. The intention is to provide data engineers and platform managers with valuable insights to enhance their decision-making process regarding data infrastructure options.
TUTORIALS
SQL cookbook for dbt: Transforming Big Data with Incremental Models | 8 min | Data Engineering | Hugo Lu | Data Engineer Things
Let's dive into the requisite dbt skills you’ll need to effectively run lots of big data dbt models quickly — and the use-case models like this apply to.
From pipelines to platform | 13 min | Data Engineering | Robert Sahlin | Data Engineering Things
Let's explore the concept of a "data flywheel" for generating value from analytical data at scale, addressing the challenges faced by data engineers, and advocating for automated communication.
Using Data Contracts with Confluent Schema Registry | 7 min | Data Engineering | Robert Yokota | Confluent Technology Blog
This tutorial will walk you through an example of enhancing a schema to be a fully-fledged data contract. The example will involve the following actions:
- Defining an initial schema for the data contract
- Enhancing the data contract with business metadata
- Adding data quality rules to the data contract
…and more
NEWS
Overcoming complexity: the biggest new dbt Cloud features from Coalesce 2023 | 6 min | Luis Maldonado | Cloud | dbt Blog
dbt Cloud has introduced major updates to address customer concerns and make data management more efficient. These enhancements, including dbt Mesh, dbt Explorer and the Semantic Layer, help data teams collaborate, track data lineage and control data platform costs more effectively.
GKE Stateful High Availability (HA) Controller | 6 min | Peter Schuurman, Akshay Ram | AI | Google Cloud Blog
GKE now has a new feature called the Stateful HA Operator, which helps manage the availability and cost of stateful applications. It allows you to control how quickly these applications can recover in case of issues and enables you to balance costs.
TOOLS
Prompt Engineering Guide | LLM
This prompt engineering guide contains all the latest papers, learning guides, models, lectures, references, new LLM capabilities and tools related to prompt engineering.
Ponder | AI
Ponder brings the best of both worlds: a fully pandas-native experience that is familiar and fast to prototype, plus the scalability and reliability of operating in a data warehouse.
DATA TUBE
OpenLineage in Airflow: A Comprehensive Guide | 25 min | Data Engineering | Maciej Obuchowski | Apache Airflow
This talk will cover the benefits of using OpenLineage, how it is implemented in Airflow, practical examples of how to take advantage of it, and what’s in our roadmap. Whether you’re an Airflow user or provider maintainer, this session will give you the knowledge to make the most of this tool.
From Parquet to Arrow to OpenLineage | 36 min | Data Engineering | Julien Le Dem | Data Council
Julien recounts his contributions to thriving open source projects in the data ecosystem and the factors behind their success, tracing the evolution from Apache Parquet to Apache Arrow, culminating in their role in OpenLineage's success in enhancing data ecosystem observability.
DAG Authoring without PhD | 24 min | Data Engineering | Rafal Biegacz and Filip Knapik | Apache Airflow
This one offers advanced insights and best practices for Airflow DAG development, designed to assist developers handling numerous Airflow operators. It caters to both beginners and experts, enhancing productivity in DAG development.
CONFS EVENTS AND MEETUPS
A High-Level Approach for Solving MLOps Challenges | Webinar | 9th November 2023
Key Takeaways:
- What signals to watch for that might mean you have MLOps Fatigue
- How to define the challenge/problem you need to solve in a way that makes finding solutions easier and faster
- A few examples on how this framework is applied to the real world, so that it’s easy to apply in practice
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
