
ARTICLES
Lessons Learned From Running Apache Airflow at Scale | 10 min read | Apache Airflow | Megan Parker | Shopify Blog
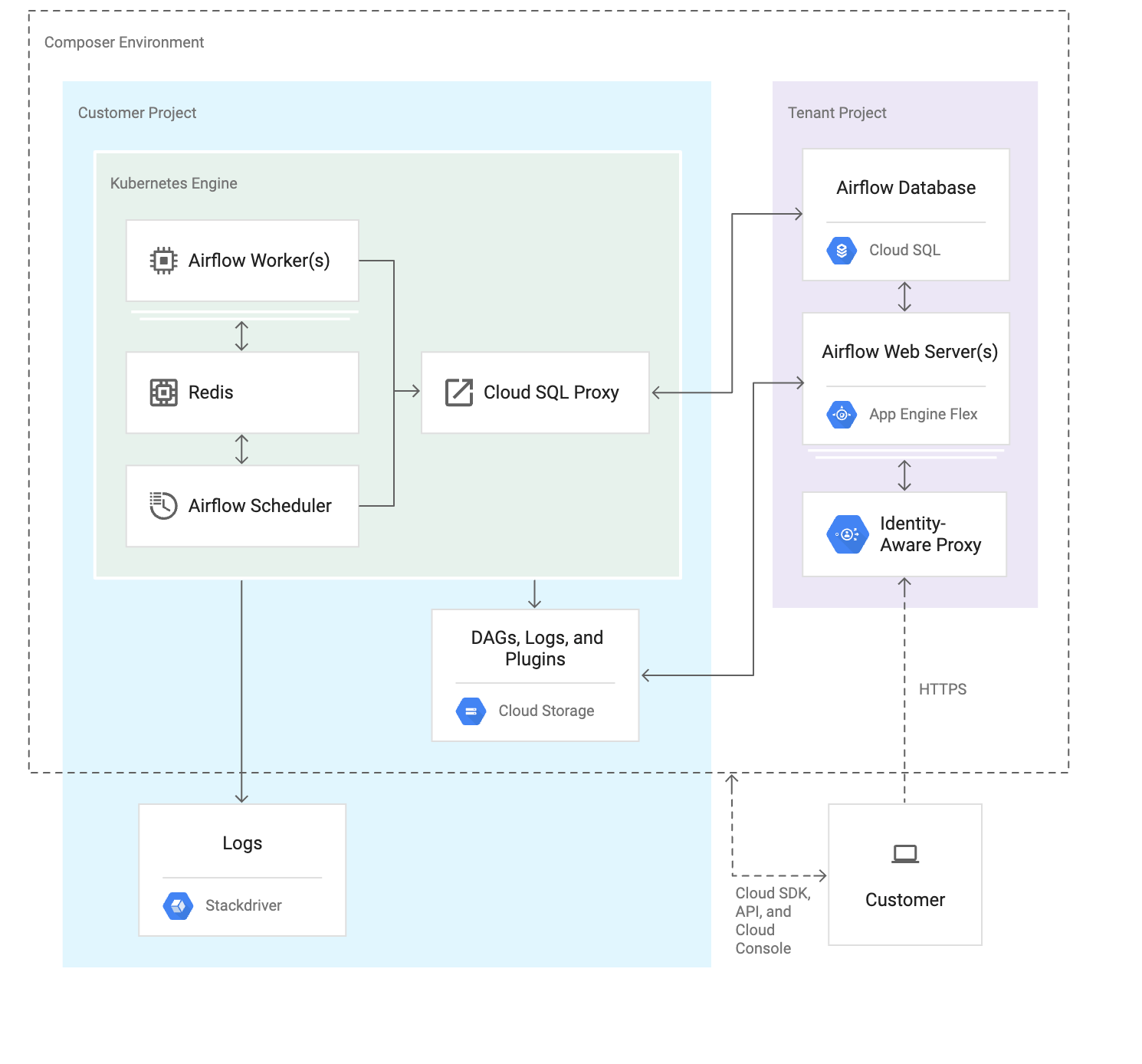
Challenges in running Airflow at scale + concrete solutions
- A combination of GCS and NFS allows for both performant and easy to use file management.
- Metadata retention policies can reduce degradation of Airflow performance.
- A centralized metadata repository can be used to track DAG origins and ownership.
One-stop MLOps portal at LinkedIn | 10 min read | MLOps| LinkedIn Blog
To visualize the entire ML lifecycle, an infrastructure is needed to automatically track every step of the machine learning process. We created a data schema to capture the complete, structured, and well-documented information detailing how machine learning models are produced.
Monitoring Large-Scale Apache Flink Applications, Part 1: Concepts & Continuous Monitoring | 12 min read | Apache Flink | Nico Kruber | Ververica Blog
This post introducees various useful metrics which can be set up with proper alerts to inform you about imminent failures and allow you to monitor cluster and application health and checkpointing progress. Different ways to track latency and observe your application’s throughput for performance monitoring
Real-time ingestion to Iceberg with Kafka Connect - Apache Iceberg Sink | 11 min read | Apache Iceberg Sink | 🎉 Grzegorz Liter | GetInData Blog
GetInData created an Apache Iceberg sink that can be deployed on a Kafka Connect instance. Data format that is consumed by Apache Iceberg has to represent table-like data and its schema, therefore we used a format created by Debezium for change data capture.
Which Managed Version Of Airflow Should You Use? | 7 min read | Apache Airflow | SeattleDataGuy
Google Cloud Composer Vs. MWAA Vs. Astronomer
Setting up MWAA or Cloud Composer is easier than setting up Astronomer. But in Astronomer You gain in customizability. Astronomer works closely with Airflow, and… it is only for Airflow only. MWAA and Cloud Composers are great solutions when you have pretty simple DAGs that you want to build. But more than likely, as your company grows and you have more complex needs, you might find yourself needing to migrate to Astronomer.
A Generalist Agent | Abstract or full report | Machine Learning | Deepmind
Transformers+large scale still have much to offer
Inspired by progress in large-scale language modelling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.
NEWS
Now generally available: BigQuery BI Engine supports many BI tools or custom application | 6 min | Google Cloud | Google Cloud Blog
With BigQuery BI Engine, we can accelerate our dashboards and reports that connect to BigQuery without having to sacrifice freshness of the data.
OpenFeature, With Contributions From eBay, Submitted to CNCF's Sandbox Program | 6 min | Cloud Nativ | Justin Abrahms | eBay Blog
Feature flagging is a mechanism that allows product delivery teams to alter application functionality at runtime without having to deploy code. From a code perspective, this looks as simple as an if statement.
Amazon Releases 51-Language AI Training Dataset MASSIVE | 6 min | Cloud Nativ | Anthony Alford | infoQ Blog
MASSIVE, a dataset for training natural language understanding (NLU) AI models that contains one million annotated samples from 51 languages. The release also includes code and tools for using the data.
PODCAST
Dataflow Automation | 47 min | The Data Exchange
Jeremiah Lowin CEO of Prefect on designing tools to allow teams to build, run, and monitor data pipelines at scale. Data engineering challenges facing data and ML teams today, and implications of looming trends in machine learning and AI are discussed.
Cloud Native Data Orchestration For Machine Learning And Data Engineering With Flyte | 1h 7 min | The Data Exchange
Flyte is a project that was started at Lyft to address their internal needs for machine learning and integrated closely with Kubernetes as the execution manager.
DATAtube
Things I Wish I Knew When I Started As A Data Engineer | 15 min | Seattle Data Guy
Lessons and advice after 10 years in data. Don't try to learn all technologies all at once - it’s gonna get you nowhere
SUPPORT Role To BUSINESS Analyst Amazon | 15 min | E-Learning Bridge
How to become Business Analyst at Amazon and what are the salaries. What is Business Analyst role in Amazon. How is this job different from other data-related jobs?
CONFS AND MEETUPS
Code Europe Warsaw | 2 June
6 different topics parts, one of them is Data & AI.
Introduction to Big Data: Amazon Web Services & Apache Spark | 8 June | Online
The speaker will discuss the latest trends in big data tools and platforms and give an introduction to AWS and Apache Spark. There will also be a demo of an end-to-end big data project shown at the end.
