
ARTICLES
Microsoft builds the bomb | 7 min | Data Analytics | Benn Stancil | Personal Blog
Last week we mentioned that Microsoft released the Fabric - A Data Platform, combining its data services into one suite. Now it is time to dig into the very interesting comments on it. Highly recommended to read, even if you don’t agree in the end.
DoorDash identifies Five big areas for using Generative AI | 6 min | AI | Alok Gupta | DoorDash Engineering Blog
Generative AI creates new content from existing data. OpenAI's GPT models are popular examples. ChatGPT, used for this response, is one such model. DoorDash can leverage Generative AI in five categories with anonymized and pseudonymized data:
- Assistance of customers to complete tasks
- Better tailored and interactive discovery
- Generation of personalized content and merchandising
- Extraction of structured information
- Enhancement of employee productivity
Let’s explore each of these in more detail.
Queues for Kafka | 9 min | Data Engineering | Andrew Schofield | Personal Blog
Let's compare two types of queues in Kafka: producer-consumer and consumer-group, the benefits of using queues in Kafka such as improved performance, better fault tolerance and easier scalability.
Applying LLMs to Enterprise Data: Concepts, Concerns, and Hot-Takes | 11 min | LLM | Sam Stone | Towards Data Science Blog
This article provides an overview of applying LLMs to enterprise data, highlighting their potential benefits and addressing ethical and practical considerations. Responsible navigation of these challenges is crucial for effectively leveraging the power of language models in enterprise settings.
Understanding LLMOps: Large Language Model Operations | 12 min | LLM | Leonie Monigatti | Personal Blog
Another one about LLM. Take a look at a comprehensive overview of LLMOps, covering the training, fine-tuning, deployment, monitoring and maintenance of large language models. It highlights the challenges and considerations involved in managing LLMs and offers insights into future directions.
TUTORIAL
Introducing the Apache Iceberg Catalog Migration Tool | 8 min | Data Engineering | Dipankar Mazumdar, Ajantha Bhat | Dremio Blog
In this one, the Dremio team introduces the iceberg-catalog-migrator tool as a simple and efficient solution for transferring Iceberg tables from one catalog to another. They discuss various situations where this tool can be advantageous and provide practical instructions on how to use it for performing such migrations.
Latency goes subsecond in Apache Spark Structured Streaming | 10 min | Data Engineering | Jerry Peng, Pranav Anand, Sourav Gulati, Karthik Ramasamy, Michael Armbrust, Matei Zaharia | Databricks Blog
This one focuses on the improvements the Databricks team have made around offset management to lower the inherent processing latency of Structured Streaming. These improvements primarily target operational use cases such as real time monitoring and alerting that are simple and stateless.
TOOLS
Karapace | Data Engineering
Worth knowing the tool for data platform engineers.
Karapace supports the storing of schemas in a central repository, which clients can access to serialize and deserialize messages. Karapace rest provides a RESTful interface for your Apache Kafka cluster, allowing you to perform tasks such as producing and consuming messages and perform administrative cluster work, all the while using the language of the WEB.
DATA TIPS & TRICKS
I've just fine-tuned a 33B-parameter LLM on Google Colab in a few hours | LLM | Itamar Golan
An insane case for any of you using open-source LLMs on normal GPUs. Itamar fine-tuned a 33B-parameter LLM on Google Colab in just a few hours.
NEWS
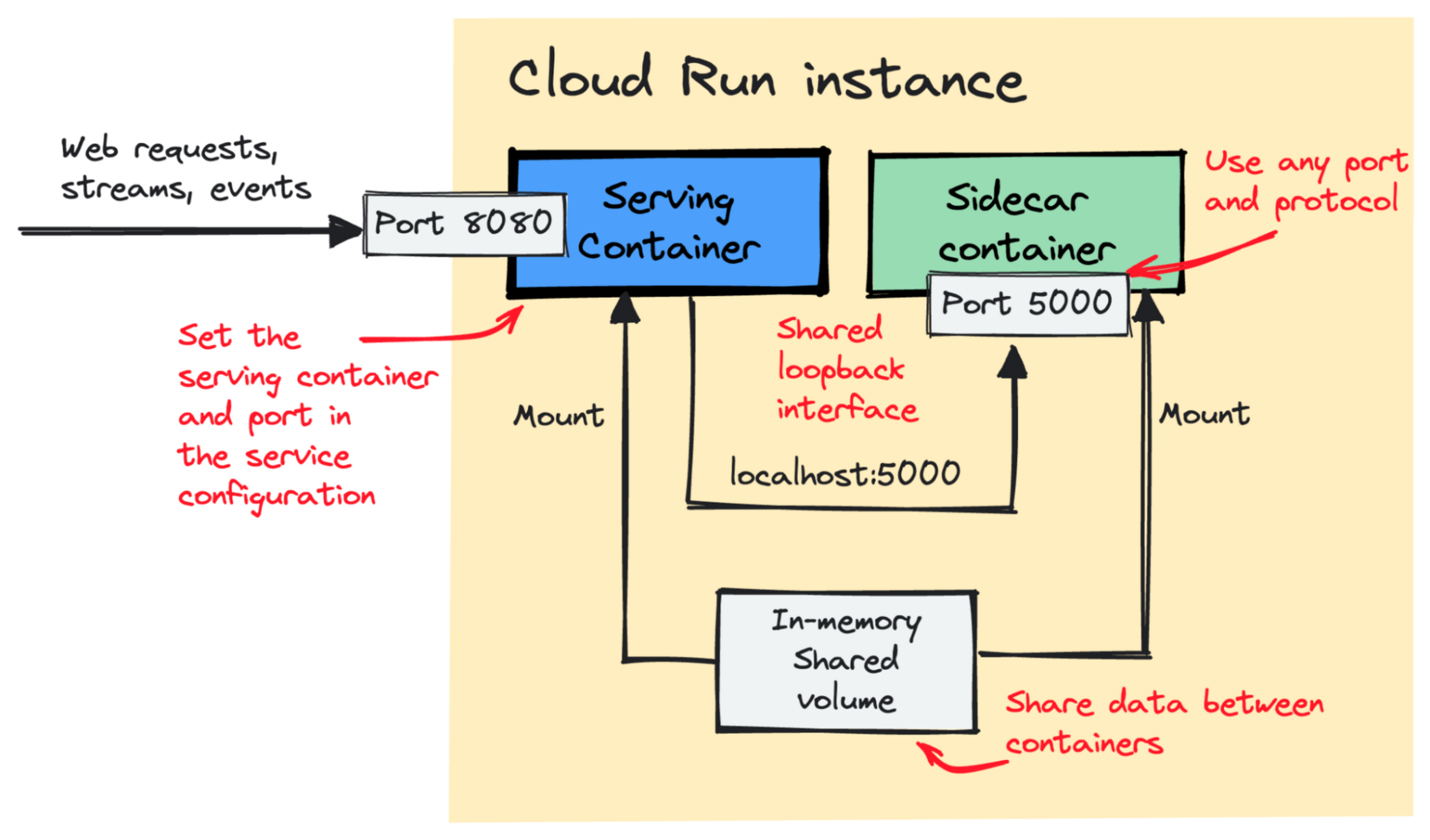
Cloud Run now supports sidecar deployments — monitoring agents, proxies and more | 5 min | Cloud | Sagar Randive | Gloogle Cloud Blog
Google's new feature enables developers to manage multiple containers in a single Cloud Run service, making it possible to build and deploy more complex applications using serverless technology.
Check out how this feature works in detail, including how it simplifies the deployment process, how it allows for better container resource allocation, and how it enables easier application scaling.
Snowflake CEO Frank Slootman: Generative AI ‘Will Bring Obsolescence to Entire Industries’ | 4 min | AI | Bob Evans | Acceleration Economy
Check Frank Slootman's opinion if generative AI will bring about the obsolescence of entire industries. Will AI replace human labor in many industries, leading to job loss and the need for workers to acquire new skills?
Read how in his opinion, companies must adapt to the changes brought about by AI to remain competitive in the global market.
Announcing the General Availability of Databricks SQL Serverless! | 3 min | SQL | Cyrielle Simeone, Shant Hovsepian, Gaurav Saraf | Databricks Blog
This blog post will highlight the advantages of DB SQL Serverless and update you on the newest features to enhance your data warehousing performance.
Databricks announces that serverless computing for Databricks SQL is now Generally Available on AWS and Azure. It guarantees unparalleled stability, support, and enterprise readiness for your mission-critical workload on the Databricks Lakehouse Platform.
PODCAST
Building AI Products with ChatGPT | 56 min | AI | Host: Richie Cotton; Guest: Joaquin Marques | DataFramed Podcast
During this talk, Joaquin and Richie discuss AI's development, its current state and future possibilities. He shares information on ongoing projects at Kanayma and tips for building AI products, including ChatGPT's impact. Let’s explore the practical consequences, technical details and real-world applications of AI, offering guidance for incorporating AI into your company's products.
CONFS EVENTS AND MEETUPS
Berlin Buzzwords | 18-20th June | Berlin
Join the conference focused on open source software projects in the field of data analysis, machine learning, scalability, storage and searchability. Not only can you discover the latest trends in the world of search with projects like Elasticsearch, OpenSearch, Solr and different vector search engines, but also learn more about projects such as Apache Flink, Spark, Kafka, MongoDB and many others.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
