
ARTICLES
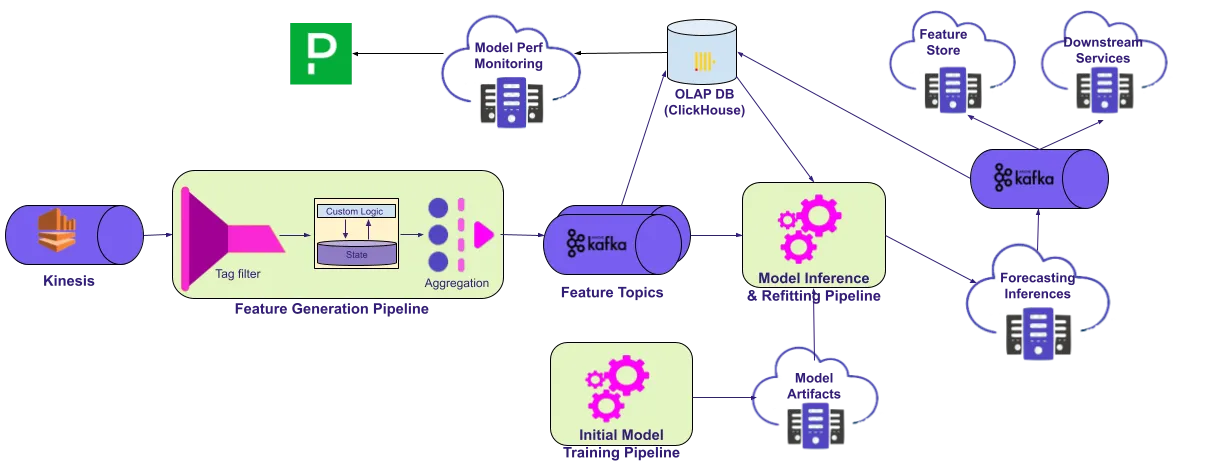
Real-Time Spatial Temporal Forecasting @ Lyft | 13 min | ML | Josh Xi, Rakesh Kumar | Lyft Engineering Blog
How Lyft predicts minute-level demand across millions of locations, balancing latency, noise, and deep vs. time series models.
Zero-copy, Coordination-free approach to OpenSearch Snapshots | 8 min | DevOps | Sachin Kale, Bukhtawar Khan, and Gaurav Bafna | AWS Blog
This blog introduces Shallow Snapshot V2 in Amazon OpenSearch Service, enabling faster, more efficient, and scalable backups using a timestamp-based system with reduced overhead.

Lakehousing: A Schema-change strategy beyond Spark’s mergeSchema | 7 min | Lakehouse Architecture | Christian Henrik Reich | Personal Engineering
A versioned schema evolution strategy for Lakehouse stacks that avoids Spark’s mergeSchema pitfalls while staying engine-flexible.
Key Areas to Plan Before Building Your Azure Data Platform | 6 min | Data Platforms | Tomasz Kostyrka | Xebia Blog
Five foundational areas—networking, IAM, IaC, CI/CD, and conventions—that will make or break your Azure data platform build.
TUTORIALS
Airflow 3 and Airflow AI SDK in Action — Analyzing League of Legends| 34 min | Data Engineering | Volker Janz | Data Engineer Things
Build an AI-powered data pipeline with Airflow 3 and Gemini, using LLMs to generate and rank tier lists from LoL match data.

Flink Materialized Table: Building Unified Stream and Batch ETL | 5 min | Data Engineering | Alibaba Cloud Blog
Unify stream and batch ETL with Flink’s declarative Materialized Table—define logic once, let Flink choose the mode.
I Fine-Tuned an LLM on 5 Years of Telegram Chats | 11 min | LLM | Alessandro Romano | Personal Blog
Step-by-step guide to training a custom chatbot using LoRA fine-tuning on five years of personal Telegram history.
NEWS
Databricks + Neon | Data Engineering | 4 min | Ali Ghodsi, Arsalan Tavakoli-Shiraji, Patrick Wendell, Reynold Xin, Matei Zaharia | Databricks Blog
Neon, the serverless Postgres startup with an AI-first dev experience, joins Databricks to power the next-gen AI-native database platform.
DATA TUBE
Moving Past Hadoop to a Modern Data Platform with Pure Storage & Dremio | Modern Data Platform | 50 min | Mark Shainman, Chad Hendren | Dremio
Best practices for migrating from Hadoop to an object storage-based Iceberg lakehouse, with performance and sustainability in focus.
CONFS, EVENTS AND MEETUPS
Machine Learning with AWS | Webinar | May 27th
Join Luca Bianchi, Field CTO at Neosperience, for a hands-on code-along session exploring key AWS tools like SageMaker and Bedrock to streamline machine learning workflows and boost your AWS skills.
PINNACLE PICKS
Your last week top picks:
Uber’s Journey to Ray on Kubernetes: Resource Management | 6 min | MLOps | Bharat Joshi, Anant Vyas, Ben Wang, Axansh Sheth, Abhinav Dixit | Uber Engineering Blog
Uber enhanced Kubernetes with custom schedulers and GPU-aware logic to scale multi-tenant Ray workloads for ML efficiently and reliably.
Building a Scalable Analytics Platform: Why Microsoft Clarity Chose ClickHouse | 6 min | Stream Analytics | Omar Bazaraa | Microsoft Clarity Blog
Learn how ClickHouse replaced Spark and ElasticSearch to power real-time analytics at massive scale for Microsoft Clarity.
Build more climate-friendly data applications with Rust | 5 min | Data Engineering | R. Tyler Croy | Buoyant Data Blog
A real-world example of replacing Kafka pipelines with Rust, cutting CO₂ emissions and cloud costs by 99%.
________________________
Have any interesting content to share in the DATA Pill newsletter?
