
ARTICLES
dream Distributed RAG Experimentation Framework | 4 min | RAG | Aishwarya Prabhat | Personal Blog
DREAM is a Distributed RAG Experimentation Framework that leverages a Kubernetes-native architecture to streamline the testing and evaluation of RAG techniques. It utilizes technologies like Ray, LlamaIndex, and MLFlow to facilitate distributed computing and detailed experiment tracking. This framework improves the efficiency of determining optimal RAG configurations for specific use cases.

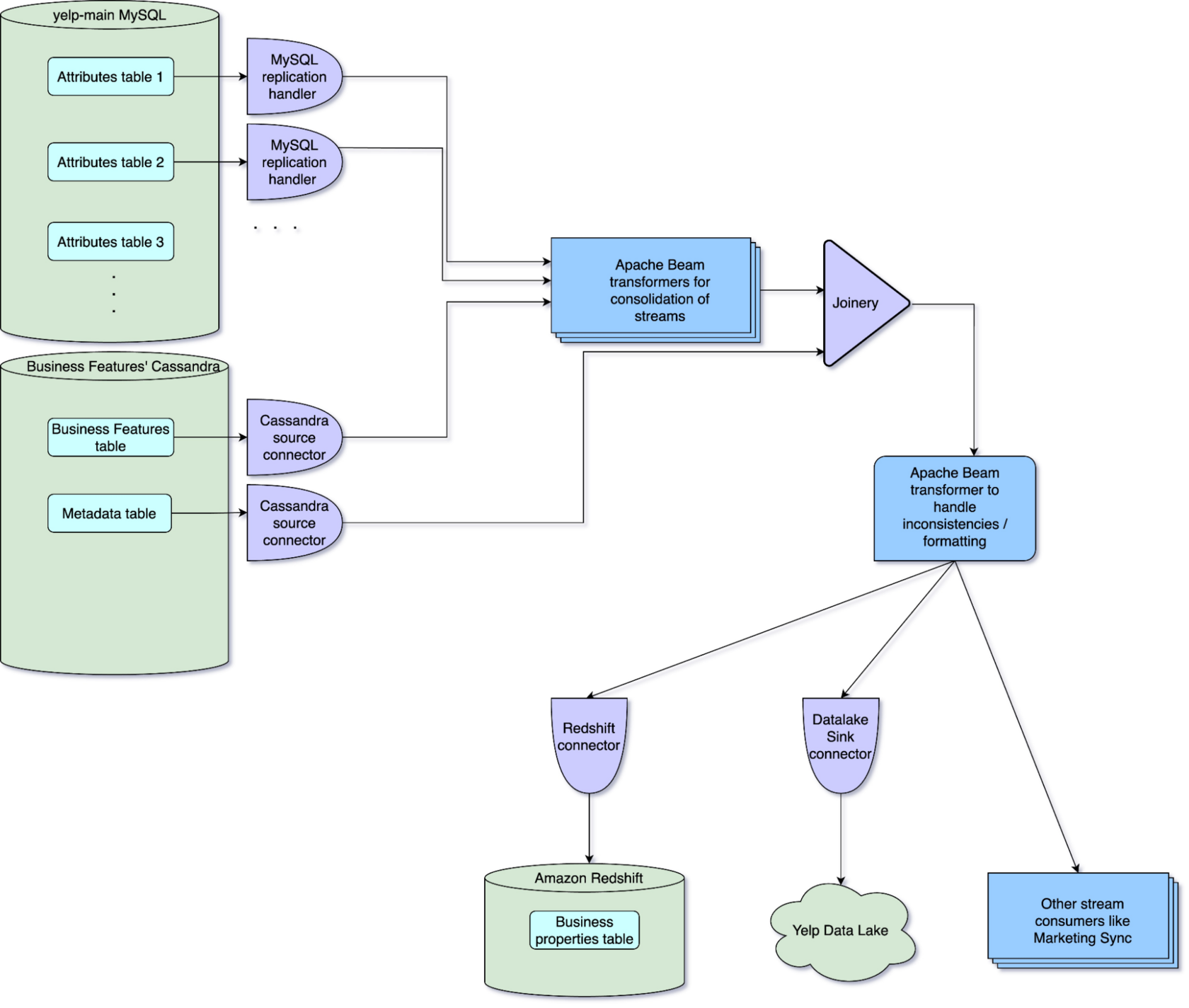
Building data abstractions with streaming at Yelp | 5 min | Data Streaming | Hakampreet Singh Pandher | Yelp Blog
This blog post explores how Yelp utilizes extensive streaming infrastructure to develop robust data abstractions for offline and streaming data consumers. It will illustrate this using Yelp’s Business Properties ecosystem, which is detailed in the following sections.
The Evolution of Real-Time Data Streaming in Business | 7 min | Data Streaming | Klaudia Wachnio | GetInData | Part of Xebia Blog
Read a blog post based on the webinar "Real-Time Data to Drive Business Growth and Innovation in 2024" and explore the transformative impact of real-time data streaming. Discover how leveraging instant data analytics is not just for tech giants but a game changer for businesses across all sectors aiming to drive growth and outpace the competition.
Unity Catalog Governance in Action: Monitoring, Reporting, and Lineage | 6 min | Data Engineering | Ari Kaplan, Pearl Ubaru | Databricks Blog
The technology behind Databricks' Unity Catalog supports a variety of business outcomes: faster innovation, cost reduction, compliance support and more. Dive into some of the capabilities that make this possible, such as Databrick’s data lineage, comprehensive monitoring + reporting, Feature Store and more.
SKILL LAKE
Introduction to Stream Processing and Apache Flink | 35 min | Data Engineering | Ververica
This foundational course blends theory, practical examples, quizzes, and a final assignment to give students a comprehensive understanding of data processing with Apache Flink. It covers modules on Flink's basics, architecture, SQL API, time handling, fault tolerance, and state backends.
BTW, we are looking for a Data Engineer with Flink. Check out the offer here.
TUTORIALS
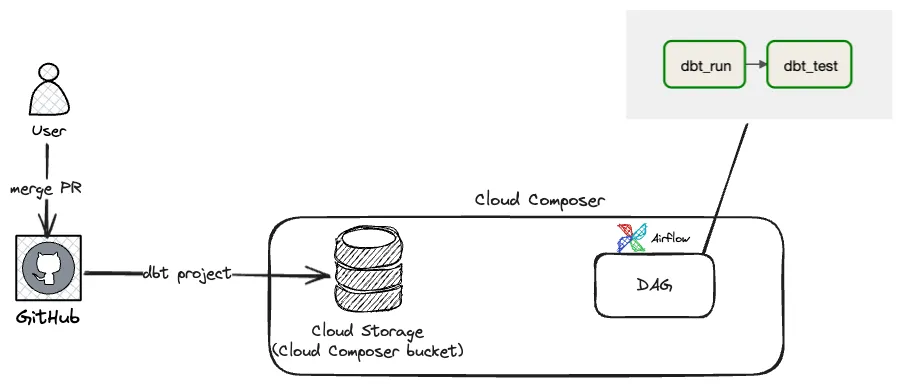
dbt + Airflow = ❤ | 12 min | Data Engineering | Giorgos Myrianthous | Making Plum Blog
To overcome limitations with dbt Cloud, the team built their own integration platform, customizing it to schedule projects, ensure task granularity, and maintain essential dbt dependencies. This strategic move significantly enhanced their control and flexibility in data operations.
Building a Smarter Shopping Experience: The Technology Behind Conversational Search in E-Commerce | 11 min | LLM | Cumhur Kinaci | Adevinta Tech Blog
Adevinta’s team has developed a conversational search tool for Leboncoin, a prominent second-hand marketplace in France, transitioning from improving user experiences with personalized recommendations. This tool simplifies user interactions by making product searches and seller connections more accessible and intuitive. It utilizes advanced natural language processing to improve the user-friendliness of the marketplace.
Harnessing the Power of Grafana and CockroachDB: Visualizing and Marking Dataset Insights | 10 min | Data Science | M Muneeb Ur Rehman | The Deep Hub
In this blog, we embark on a journey to explore how this powerful combination can revolutionize your approach to data analysis and decision-making.
Efficiently fine-tune Llama 3 with PyTorch FSDP and Q-Lora | 9 min | LLM | Philipp Schmid | Personal Blog
This blog post walks you thorugh how to fine-tune a Llama 3 using PyTorch FSDP and Q-Lora with the help of Hugging Face TRL, Transformers, peft & datasets.
DATA TUBE
50 Years of SQL | 39 min | Data Analytics | Don Chamberlin | DataCamp
Don Chamberlin is renowned as the co-inventor of SQL. In the episode, Richie and Don explore his early career at IBM and the development of his interest in databases alongside Ray Boyce, the database task group (DBTG), the transition to relational databases and the early development of SQL, the commercialization and adoption of SQL, how it became standardized, how it evolved and spread via open source, the future of SQL through NoSQL and SQL++ and much more.
CONFS EVENTS AND MEETUPS
Effortless Data Orchestration: A Practical Guide to Azure Data Factory and Snowflake | Online | 29th May
Get hands-on with Azure Data Factory and Snowflake. You will demystify ETL/ELT and DataOps to streamline your data pipelines and analytics workflows. You will learn how to seamlessly integrate, transform, and optimize data processing with intuitive, powerful tools.
In this lab, you'll:
- You can easily set up and run data pipelines in ADF, connecting to various sources and using intuitive tools for efficient ETL.
- Integrate ADF and Snowflake smoothly, translating data into actionable analytics.
- Utilize ADF data flows for smart data shaping from Azure SQL to Snowflake, readying your data for insight generation.
- Leverage Snowflake's push-down computing for better data processing performance.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
