
ARTICLES
Supercharging A/B Testing at Uber | 11 min read | Data Science | Sergey Gitlin, Krishna Puttaswamy, Luke Duncan, Deepak Bobbarjung, and Arun Babu | Uber Blog
A very in depth read with an analysis of Uber's new testing platform project.
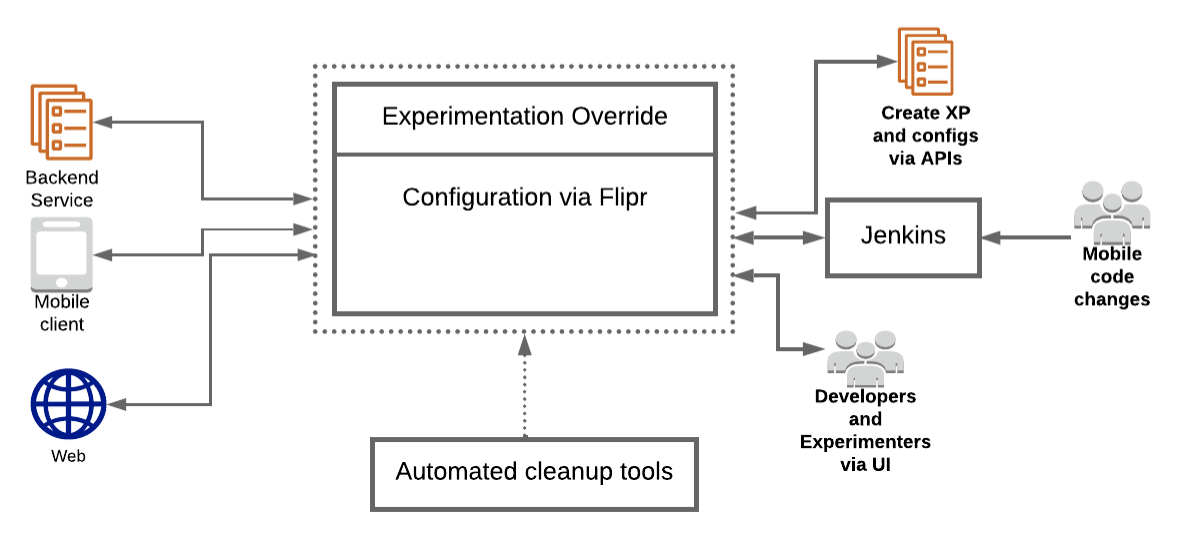
Uber had an experimentation platform called Morpheus that was built 7+ years ago in the early days to do both feature flagging and A/B testing. Uber has outgrown Morpheus significantly since then in terms of scale, users, use cases etc, therefore Morpheus became insufficient. In 2020, Uber took on the challenge of creating a new testing platform.
In this article, you will find out what the assumptions of the project were, how the implementation went and what were the conclusions.
Continuous Deployment at Lyft | 7 min read | Deployment | Miguel Molina | Lyft Blog
Lyfts result in automatic deployment: the number of commits per production deploy has significantly decreased from around 3 to around 1.4. Fewer commits per deploy means changes in production are more predictable and easier to monitor.
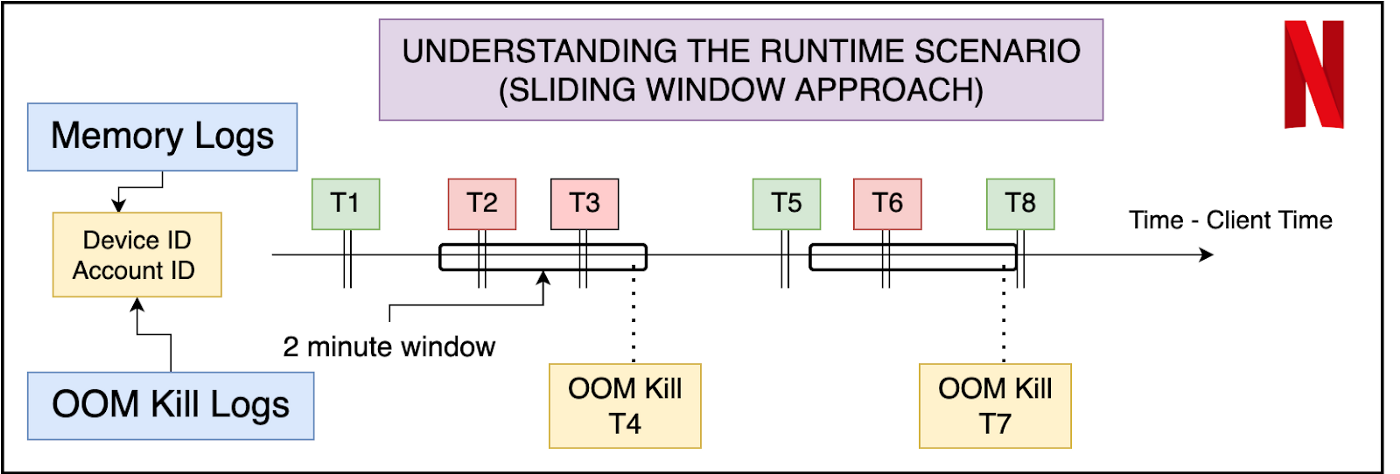
Formulating ‘Out of Memory Kill’ Prediction on the Netflix App as a Machine Learning Problem | 9 min read | ML | Aryan Mehra | Netflix Blog
An insight into analyzing and predicting “out of memory” or OOM kills on the Netflix App.
Data-Centric Machine Learning: Building Shopify's Inbox Message Classification Model | 15 min read | Data Science | Eric Fung | Shopify Blog
A journey through building a message classification model for Shopify's Inbox by applying the data-centric approach. The model aim is to help merchants prioritize responses that would convert into sales and guide our product team on what functionality to build next.
Some abstract from the results:
Model accuracy:
version 1.0 ~70%
version 2.0 ~90%
High confidence coverage:
version 1.0 ~35%
version 2.0 ~80%
Fraud Detection With Cloudera Stream Processing Part 2: Real-Time Streaming Analytics | 10 min read | Apache Flink | André Araújo | Cloudera Blog
In this blog we will explore how we can use Apache Flink to get insights from data at lightning-fast speed, utilizing Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). We will also use the information produced by the streaming analytics jobs to feed different downstream systems and dashboards.
BTW - here is nice Flik related position in very interesting project.
NEWS
Power to the SQL People: Introducing Python UDFs in Databricks SQL | 4 min read | Databricks Blog
Databricks SQL introduces Python UDFs.
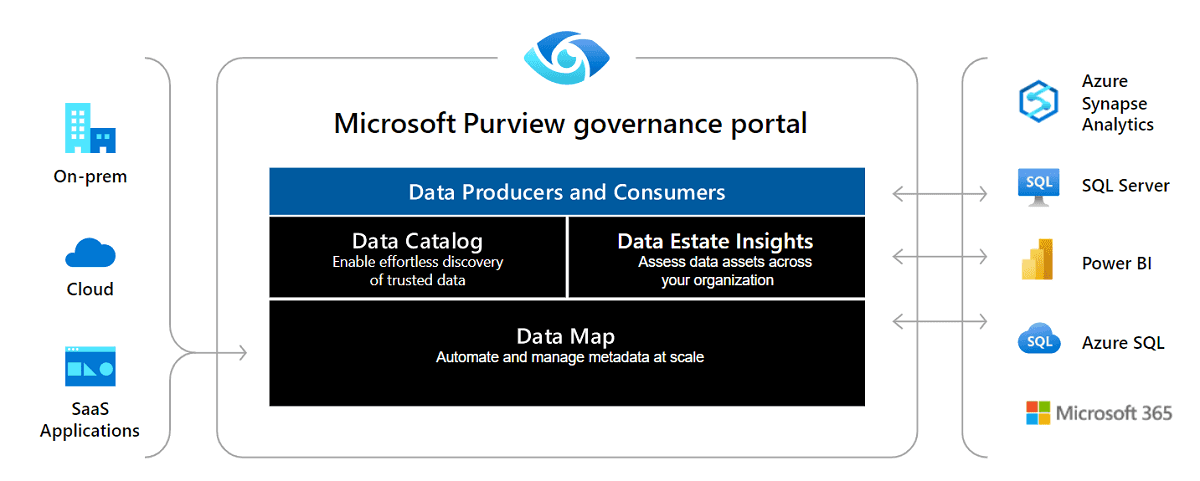
Microsoft Purview Accelerates Lineage Extraction from Azure Databricks | 7 min read | OpenLineage Blog
Lineage extraction is now possible for Azure Databricks and Microsoft Purview users. Thanks to a robust OpenLineage Spark integration, users can both extract and visualize lineage from their Databricks notebooks and jobs inside Microsoft Purview.
Btw. A high five to our community members who contributed to this project:
- Paweł Leszczyński, Data Engineer, GetInData (@pawel-big-lebowski)
- Tomasz Nazarewicz, Data Engineer, GetInData (@tnazarew)
- Maciej Obuchowski, Software Engineer, GetInData (@mobuchowski)
TUTORIALS
4 Must-Have Tests for Your Apache Kafka CI/CD with GitHub Actions | 4 min read | Apache Kafka CI/CD | Yeva Byzek | Confluent Blog
The headline says it all.
PODCAST
Data Journey with Wouter de Bie (Datadog) - Multi-cloud developer experience, Datadog vs. Spotify, areas to watch in the data landscape | 47 min | AI | Radio DaTa
What Datadog is, who uses it, what data it collects, and how data is used in their product. Multi-cloud developer experience at Datadog (technology stack, cloud providers, open-source). Future plans for the evolution of the data platform at DatadogDifferences between Datadog and Spotify in the context of building the data platform, goals, and challenges. Important patterns that one can notice when working with big data for 12 yearsGaps and areas to watch for new tools/products in the data landscape.
Mark Chen on building AI models for image generation | 38 min | AI | The Data Exchange
Mark Chen is a Research Scientist at OpenAI and part of the team behind DALL·E 2, a new AI system that can create realistic images and art based on natural language descriptions. In the podcast:
- novel applications of DALL·E, key research developments that led them to DALL·E 2.
- how DALL·E is built including the data they use, the safety and quality assurance tests they have in place, and the ML models needed to make DALL·E 2 work.
DataTube
Snowflake Vs Databricks - A Race To Build THE Cloud Data Platform | 13 min | SeattleDataGuy
Two data storage solutions that started in very different worlds converging on the data platform.
Both want to be your one stop shop.
Your data warehouse and data lake
Your data lakehouse...
But really they want to be your data operating system.
CONFS AND MEETUPS
How to automate decisions and scale-out SME knowledge? | 4 August | Warsaw | Marek Bubala | Goldman Sachs
You will learn:
- How to avoid bottlenecks resulting from hard-coding domain knowledge into inflexible systems.
- How to formalize and automate day-to-day decisions, at scale.
