
ARTICLES
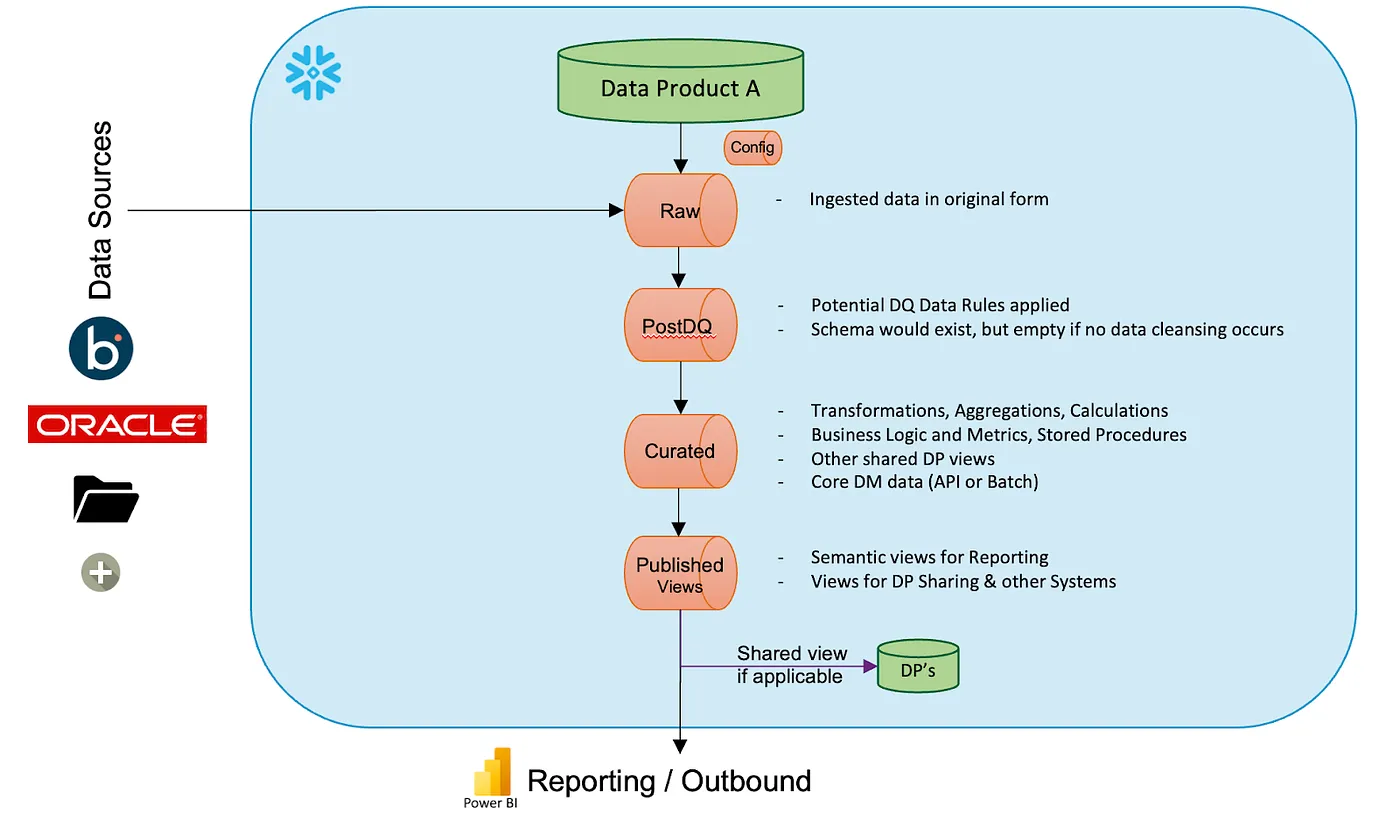
How Pfizer Achieved Self-Service Data Mesh with Snowflake and Azure | 20 min | Data Engineering | Samia Rahman, Marty Hall, Gary Kretzschmar, Christopher Witcher, Jennifer Yoakum, Matthew Massey | Snowflake Blog
This article delves into the strategic deployment of data mesh on platforms like Snowflake and Azure, offering insights from those who have successfully navigated the journey. Through the lens of Pfizer's Data Strategy, Science, and Solutions team, let's explore the pivotal shifts necessary to achieve a robust self-service data ecosystem, illustrating the challenges and triumphs along the way.
Data Lakehouses, Post-Modern Data Stacks and Enabling Gen AI: The Rittman Analytics Guide to Modernising Data Analytics in 2024 | 9 min | Data Analytics | Mark Rittman | Rittman Analytics Blog
This blog answers two of the most common questions the Rittman Analytics team gets asked by organizations looking to modernize and scale up their data stack in 2024:
- Whether it's their first data analytics project or a bid to modernize their existing analytics capability, what do they need to consider when planning a data analytics project, and what goes into a successful business case?
- What are the typical components in a "post-modern" data stack that they'd deploy for clients today, one that balances modern, composable cloud-hosted technology with the security and management needs of larger, more mature organizations?
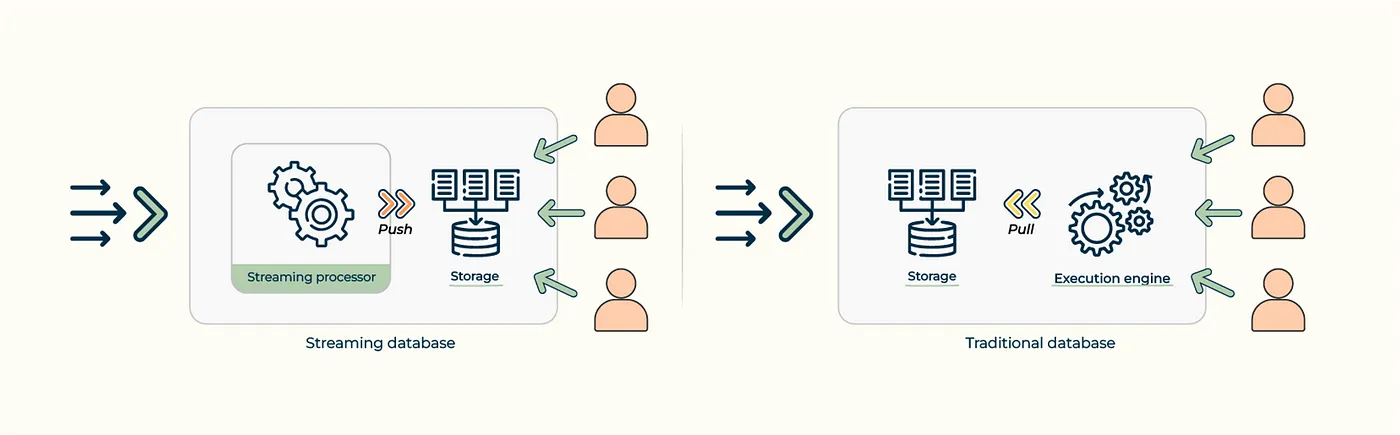
What Is a Streaming Database? | 6 min | Real-time analytics | RisingWave Labs | Towards Dev
Streaming databases are designed to process and store large volumes of real-time data, enabling immediate analysis and insights. Unlike traditional batch-processing databases, they handle continuous data flow and are ideal for time-sensitive applications like fraud detection and IoT. These databases support real-time analytics by combining immediate data processing with persistent storage.
NEWS
torchtune: Easily fine-tune LLMs using PyTorch | 3 min | LLM | PyTorch Blog
torchtune, a PyTorch library for fine-tuning large language models, has already launched. It offers modular components for training on various GPUs and covers the complete fine-tuning cycle—from dataset preparation to evaluation and local inference, including progress logging and model quantization.
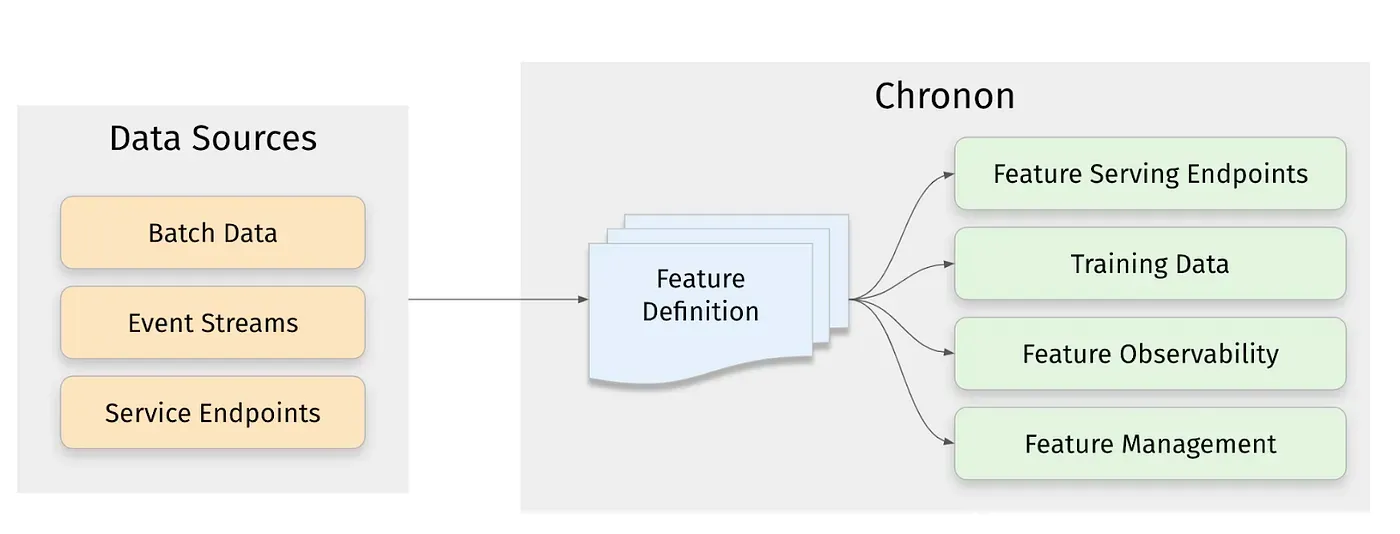
Chronon, Airbnb’s ML Feature Platform, Is Now Open Source | 9 min | ML | Varant Zanoyan, Nikhil Simha Raprolu | Airbnb Tech Blog
A feature platform that offers observability and management tools, allows ML practitioners to use a variety of data sources, while handling the complexity of data engineering, and provides low latency streaming.
SKILL LAKE
Quantization Fundamentals with Hugging Face | 1 h | LLM | Younes Belkada, Marc Sun | deeplearning.ai
Join this course to:
- Quantize any open source model with linear quantization using the Quanto library.
- Get an overview of how linear quantization is implemented. This form of quantization can be applied to compress any model, including LLMs, vision models, etc.
- Apply “downcasting,” another form of quantization, with the Transformers library, which enables you to load models in about half their normal size in the BFloat16 data type.
By the end of this course, you will have a foundation in quantization techniques and be able to apply them to compress and optimize your own generative AI models, making them more accessible and efficient.
TUTORIALS
Flink SQL—Misconfiguration, Misunderstanding, and Mishaps | 15 min | Data Streaming | Robin Moffatt | decodable blog
Dive into adventures troubleshooting some gnarly Apache Flink problems ranging from the simple to the ridiculous…
Topics covered:
- What's Running Where? (Fun with Java Versions
- What's Running Where? (Fun with JAR dependencies)
- What's Running Where? (Not So Much Fun with Hive MetaStore)
- The JDBC Catalog
- A JAR full of Trouble
- Writing to S3 from Flink
How to Build an End-to-End ML Pipeline in 2024 | 24 min | ML | Alon Lev | Qwak Blog
Let's explore a crucial element of ML: creating a system that seamlessly transitions from raw data to a continuously updated model in production, which automatically retrains itself according to set conditions.

DATA TUBE
What's new with BigQuery | 46 min | Data Engineering | Oliver Ratzesberger, Irina Farooq, Steffen Grimmel, Brian Welcker | Google Cloud
Learn the latest innovations for BigQuery to support all data, be it structured or unstructured, across multiple and open data formats, and cross-clouds; all workloads, be they Cloud SQL, Spark, or Python; and built-in AI, to supercharge the work of data teams and unlock generative AI across new use cases.ce
CONFS EVENTS AND MEETUPS
streamon: Dare to (Data) Stream BIG | Cupola XS, Haarlem, Netherlands | 25th June
Evoura and Ververica are very excited to join forces to welcome you to StreamON - an exclusive event dedicated to exploring the power and innovative use cases of data streaming. This one-day, in-person event will feature expert speakers sharing streaming data use cases, strategies, and tech deep dives.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
