
ARTICLES
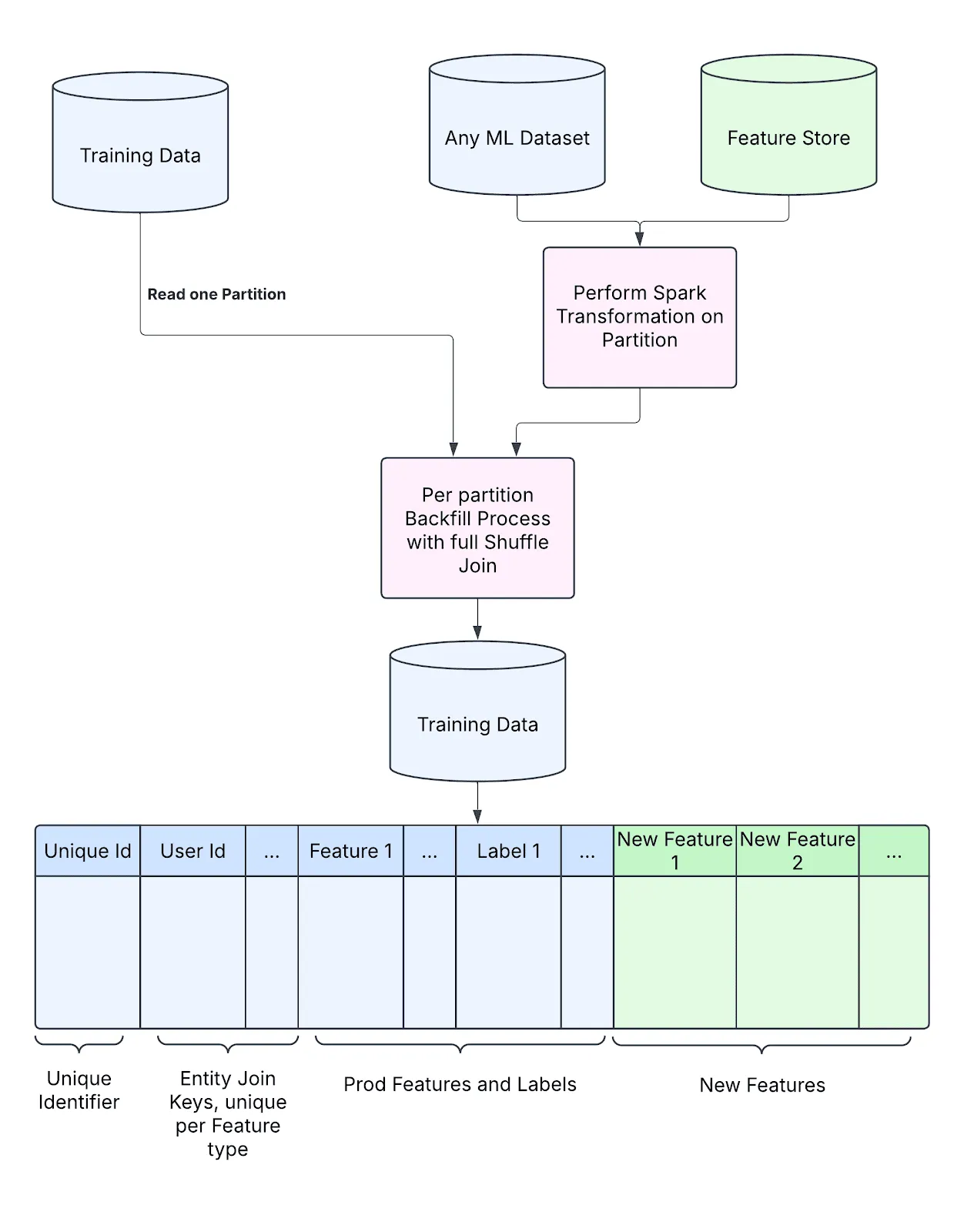
How Pinterest Accelerates ML Feature Iterations via Effective Backfill| 12 min | ML | Kartik Kapur, Matthew Jin, Qingxian Lai | Pinterest Engineering Blog
Backfilling training data can be slow and clunky. Pinterest built a faster pipeline using Iceberg and Ray—cutting down on delays and letting teams ship better features, faster.
Journey to 1000 models: Scaling Instagram’s recommendation system | 6 min | Recommendation Systems | Luke Levis, Sing Sing Ma, Eduardo Nava | Meta Engineering Blog
Instagram grew its rec system to 1,000+ ML models with tools like a model registry and auto-launch infra—keeping launches fast and model quality high.
How I Cut Docker Image Size by Switching to a Distroless Base Image | 9 min | DevOps | Dorian Grasset | Teads Engineering Blog
Going distroless, multi-stage builds, and running as non-root helped trim a Node.js Docker image from 380MB to 60MB. Cleaner, faster, and more secure.
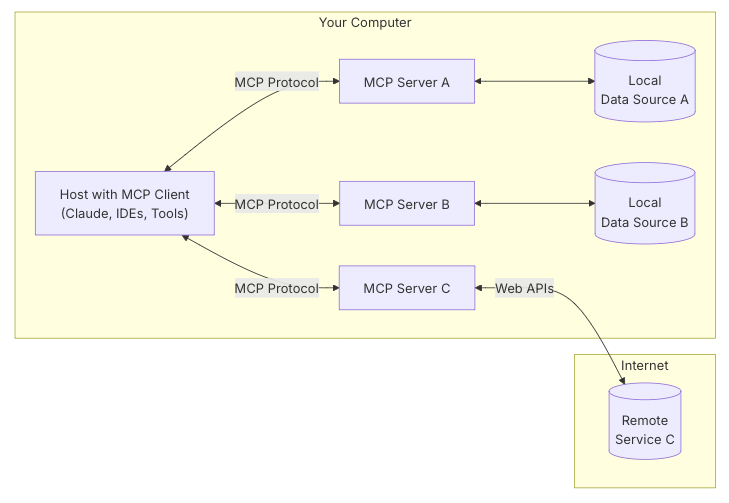
MCP: future automation killer or a promise to be kept? | 4 min | AI | Giovanni Lanzani | Xebia Blog
The Model Communication Protocol could be the standard for how AI agents talk to tools and APIs. Still early, but full of potential.
Can AI Replace Software Architects? I Put 4 LLMs to the Test | 18 min | AI | Level Up Coding
Four LLMs tried designing a crypto exchange architecture. Results? Grok stood out, but humans still hold the edge—especially those who use AI well.
TUTORIALS
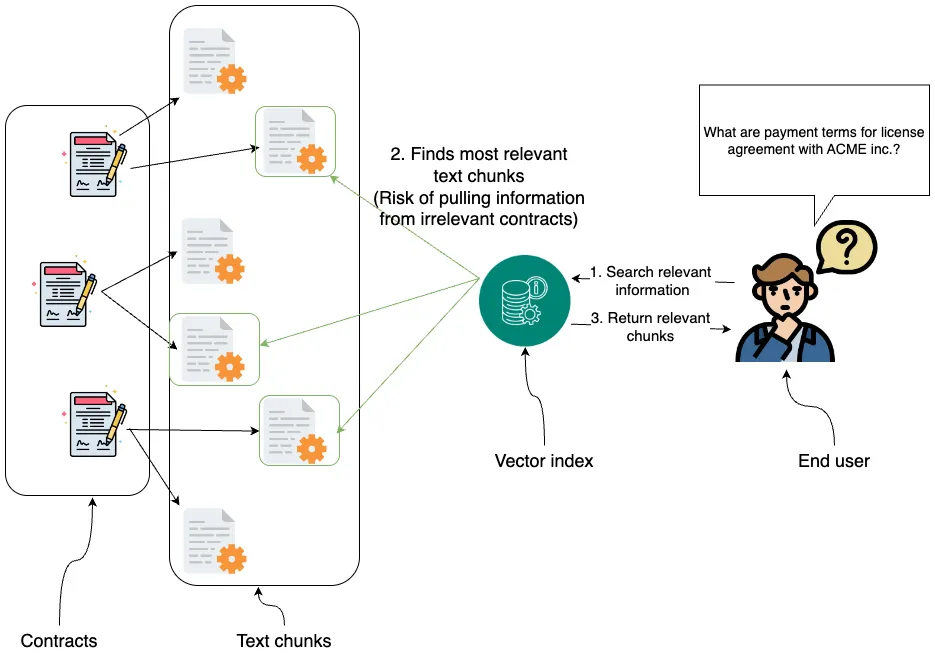
Agentic GraphRAG for Commercial Contracts | 21 min | RAG | Tomaz Bratanic | Personal Blog
Build a system that reads and queries legal contracts using a graph-based RAG setup. Great example of structured retrieval for messy data.
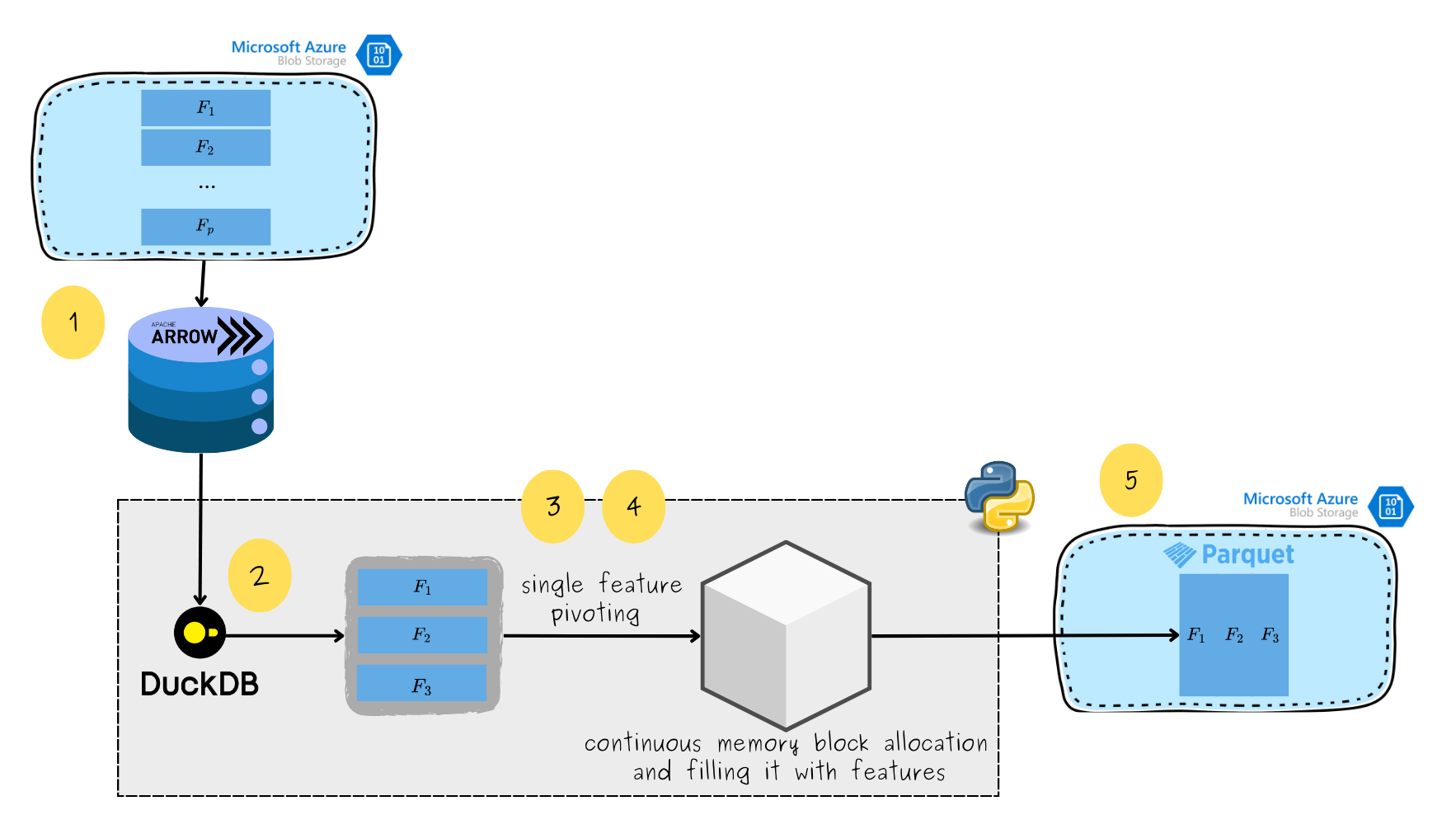
Unlock faster data processing for Machine Learning: reducing pivoting time from hours to minutes | 7 min | ML | Michał Gozdera | Allegro Tech Blog
Allegro sped up data pivoting by ditching Pandas and hacking Snowflake’s object_agg. Major boost for ML preprocessing at scale.
PODCAST
StarRocks: Bridging Lakehouse and OLAP for High-Performance Analytics | Data Engineering | 59 min | Sida Shen, Tobias Macey | Data Engineering Podcast
Sida Shen explains how StarRocks bridges lakehouse and OLAP needs—real-time joins, low latency, and support for open formats like Iceberg and Delta Lake.
DATA TUBE
Unifying Batch and Streaming in the Age of AI | AI | 1 h 31 min | Shaun Clowes, Addison Huddy, Ahmed, Saef Zamzam, Robin Sutara, Dora Simroth, Jay Kreps | Confluent
A deep dive into how Confluent is blending batch and streaming to power real-time AI systems. Includes product updates and customer stories.
CONFS, EVENTS AND MEETUPS
Data Lakehouse Storage Layer - openness, interoperability and performance | Webinar | May 27th
Join this session to explore the data lakehouse storage layer—formats like Parquet and Avro, open tables like Delta, Hudi, and Iceberg, plus tips on performance tuning, encryption, and GDPR-compliant data handling. A live demo is included.
Bonus: Register and you’ll also get on-demand access to the recording of the previous webinar in the series.
PINNACLE PICKS
Your last week top picks:
Airflow 3 and Airflow AI SDK in Action — Analyzing League of Legends | 34 min | Data Engineering | Volker Janz | Data Engineer Things
Build an AI-powered data pipeline with Airflow 3 and Gemini, using LLMs to generate and rank tier lists from LoL match data.
Real-Time Spatial Temporal Forecasting @ Lyft| 13 min | ML | Josh Xi, Rakesh Kumar | Lyft Engineering Blog
How Lyft predicts minute-level demand across millions of locations, balancing latency, noise, and deep vs. time series models.
Lakehousing: A Schema-change strategy beyond Spark’s mergeSchema | 7 min | Lakehouse Architecture | Christian Henrik Reich | Personal Engineering
A real-world example of replacing Kafka pipelines with Rust, cutting CO₂ emissions and cloud costs by 99%.
________________________
Have any interesting content to share in the DATA Pill newsletter?
