
ARTICLES
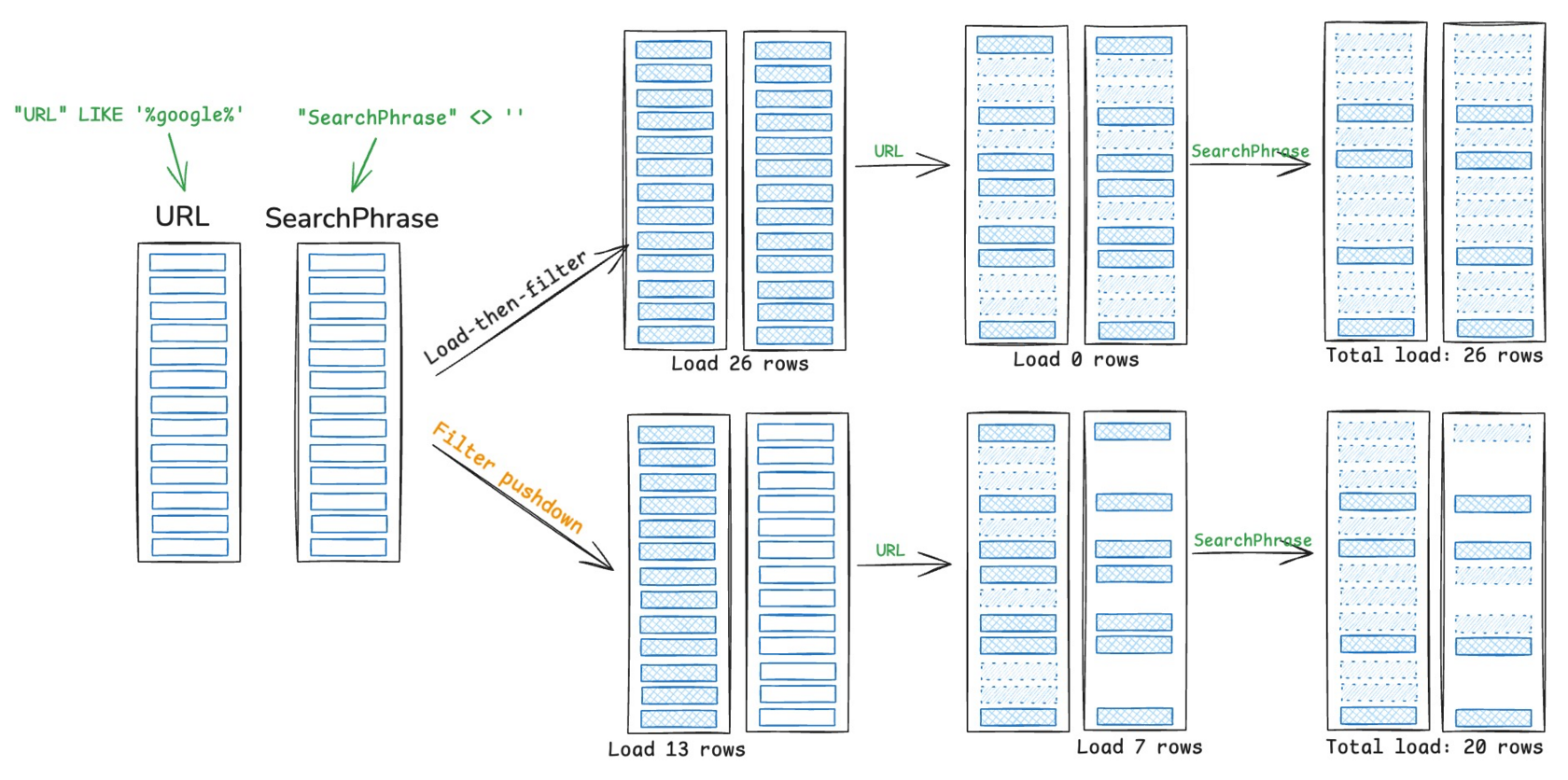
Parquet pruning in DataFusion | 3 min | Data Engineering | Xiangpeng Hao | Personal Blog
DataFusion boosts query performance with Parquet pruning, cutting I/O and processing time through optimized data retrieval.
UniLink: Your Universal “Tableflow” for Kafka—At Your Fingertips | 15 min | Data Streaming | Sijie Guo | StreamNative Blog
UniLink offers seamless real-time data replication between Kafka clusters and data lakehouses, without vendor lock-in.
TUTORIALS
Using Amazon S3 Tables with Amazon Redshift to query Apache Iceberg tables | 7 min | Data Engineering | Jonathan Katz, Satesh Sonti | AWS Blog
Set up S3 tables and run efficient analytics with Redshift Serverless and Apache Iceberg integration.

Vertex AI pipelines: catching cache complexity | 4 min | Machine Learning | Roy van Santen Roy van Santen | Xebia Blog
Vertex AI pipeline caching improves efficiency by reusing intermediate outputs, reducing costs, and speeding up development.
NEWS
A new era of data engineering: dbt Copilot is GA | 3 min | Data Engineering | Chakshu Mehta, Tom Grabowski | dbt Blog
dbt Copilot, an AI-powered data assistant from dbt Labs, is transforming data engineering by dbt Copilot automates routine data tasks with AI, integrating metadata context to boost accuracy and streamline data engineering workflows.
TOOLS
TImeplus Proton is a lightweight stream processing engine that leverages ClickHouse to manage multi-stream JOINs and incremental materialized views.
A declarative programming model that unifies reasoning-based query pipelines for structured and unstructured data with a Pandas-like API.
PODCAST
Kubernetes at LinkedIn | DevOps | 42 min | Ahmet Alp Balkan, Ronak Nathani | Kubernetes Podcast from Google
LinkedIn engineers share insights on running Kubernetes at scale and lessons learned along the way.
PODCAST
Tableflow: Materialize Apache Kafka® Topics as Apache Iceberg™ and Delta Lake Tables With Zero ETL | Data Engineering | 17 min | Tim Berglund | Confluent Developer
Tableflow simplifies data pipeline management by materializing Kafka topics as Apache Iceberg and Delta Lake tables without the need for ETL.
CONFS, EVENTS AND MEETUPS
Data & AI Warsaw Tech Summit 2025 | Warsaw and Online | 9-10th April
Join over 600 attendees and 90 speakers for technical sessions, workshops, and networking opportunities in one of the biggest Big Data events of the year.
PINNACLE PICKS
Your last week top picks:
Date Lakehouse - is it a holy grail we have been looking for?| Online | 15th April
Explore how LLM confidence scores help filter poor-quality responses, improving AI reliability in customer support and automated workflows.
The Future of AI Agents is Event-Driven | 12 min | AI | Sean Falconer | Personal Blog
Discover how Event-Driven Architecture empowers AI agents to communicate asynchronously and scale without rigid dependencies, enabling adaptive and resilient AI systems.
Every System is a Log: Part 1, Part 2 | 33 min | Data Architecture | Stephan Ewen, Jack Kleeman, Giselle van Dongen | Restate Blog
Master building real-time data pipelines by combining Apache Flink’s Java API with SQL for efficient data ingestion and processing.
________________________
Have any interesting content to share in the DATA Pill newsletter?
