Before we begin, we have a huge announcement to make!
Our community has become a partner of the biggest Big Data Conference in Northern Poland:
DataMass Summit.
This is another step in our project towards knowledge-sharing, so we are kind of… proud ;)
And for this occasion, we have a 10% discount code (ON code, no No-code ;)):
DATAPILL10
More about DataMass in the conference section.
But before we get to that, a looooot about dbt, GCP and “the Office” meme.
ARTICLES
The Modern Data Stack Through ‘The Gervais Principle’ | 17 min read | Data Flow | Lauren Balik from Upright Analytics on Medium
This one gets off to an interesting start: Data doesn’t move left-to-right in an organization, it moves through Losers, the Clueless and Sociopaths.
What if we looked at data flow in terms of the pathological nature of organizations on a vertical axis, not a horizontal one?

Orchestrating dbt Google Cloud PART 2 | 10 min read | dbt &GCP | Enrique Lopez de Lara | Pythian Blog
In this article Enrique defines and demonstrates how to deploy some Google Workflows to orchestrate tasks.
End-to-End DBT project in Google Cloud Platform (Part 1) | 11 min read | dbt &GCP | Mohamed Dhaoui | Dev Genius Blog
One more series of posts - very detailed! All about running dbt projects on GCP and building a dbt-based data platform!
Part 1: Main concepts around DBT and how to organize a DBT project and run it on Google BigQuery
Part 2: How to package the DBT project and deploy it onto the Google Cloud Platform
Part 3: Gives precise details about running dbt with Workflows.
Serverless Messaging: Latency Compared | 5 min | AWS | Bite-Sized Serverless
A comparison of the AWS serverless messaging systems.
SQS Standard can deliver a message to a consumer in as fast as 14 ms and is seldomly slower than 100 ms, assuming low batch sizes. Kinesis with Enhanced Fan-Out is only slightly slower and allows for multiple consumers and a long history of events.
Since we're talking about AWS, here's a role in an interesting AWS project.
The Modern Metadata Platform: What, Why, and How? | 13 min read | Data Stock | Mars Lan | Metaphor Blog
Metadada management seemed to be a solved problem. With the Modern Data Platform and democratisation of data, we let a bunch of new folks into this candy store with data, which means new challenges. Metadata started to look and smell like a Big Data problem. The idea on how to keep everything intact is a Modern Metadata Platform. Written by the authors of DataHub (now developing their own product: metaphor.io) with a nice walkthrough from the need to the solution.
Serverless dbt on Google Cloud Platform | 9 min read | dbt &GCP | Robert Sahlin | Robert’s Personal Blog
A step-by-step guide to running dbt in a self-hosted and collaborative setup.
How to efficiently write millions of records in the cloud and not go bankrupt — an Azure CosmosDB case study | 15 min | Cloud | Kamil Starczak | Allegro Tech Blog
At Allegro Pay they’re using Azure’s no-SQL database, Cosmos DB. It does a great job when it comes to handling operations on individual records. However, what if Allegro wanted to change the status of 10 million users based on some external analytic query? And do it on a daily basis? In this blog post, Kamil shares the technical aspect of this challenge and conclusions like:
It’s worth making data-based decisions — do the PoCs, and experiments and watch the metrics. This is exactly what we did here to get to the final and optimal solution.
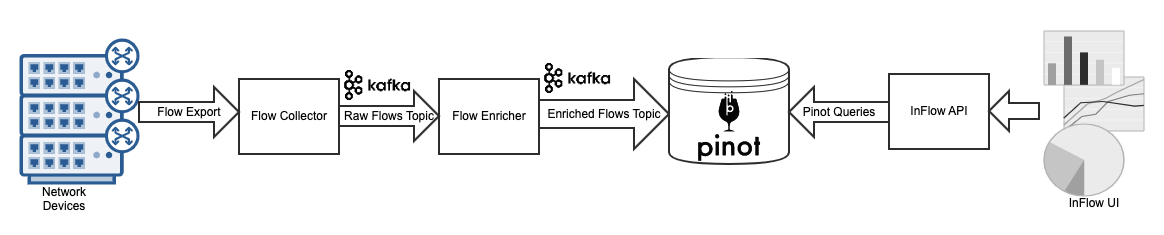
Real-time analytics on network flow data with Apache Pinot | 15 min | Data Flow | Ananya Shandilya | LinkedIn Blog
At LinkedIn, they developed InFlow to provide observability into network flows.
InFlow receives 50k flows per second from over 100 different network devices on the LinkedIn backbone and edge devices. The InFlow collector receives and parses these incoming flows, aggregates the data into unique flows for a minute, then pushes them to a Kafka topic for raw flows.
McDonald’s event-driven architecture: The data journey and how it works | 4 min | Data Flow | Vamshi Krishna Komuravalli & Damian Sullivan | Global Technology Blog
About McDonald’s unified eventing platform designed to provide a scalable, secure and reliable real-time data flow between services and applications across different domains. How it works and how the data flows through the system
NEWS
Announcing Public Preview of Data Lineage in Unity Catalog | 5 min read | Data Lineage | Paul Roome, Sachin Thakur and Tao Feng | Databricks Blog
Better late than never ;) Databricks have finally announced the public preview of data lineage in Unity Catalog, available on AWS and Azure.
Announcing the GetInData Modern Data Platform - a self-service solution for Analytics Engineers | 10 min read | Data Platform | Michał Rudko | GetInData Blog
The Modern Data Platform (or Modern Data Stack) is on the lips of basically everyone in the data world right now. The need for a more self-service approach towards data-driven insight development has been observed in many of our clients for some time now.
- What’s the deal with MDP and what was the motivation to create such a platform?
- Architecture and Data Platform framework.
Announcing the PyTorch Foundation: A new era for the cutting-edge AI framework | 9 min read | AI | Meta Blog
PyTorch will transition to a newly launched PyTorch Foundation, which will be part of the nonprofit Linux Foundation, a technology consortium whose core mission is the collaborative development of open source software. (...) Decisions will be made in a transparent and open manner by a diverse group of members for many years to come.
DATA LIBRARY
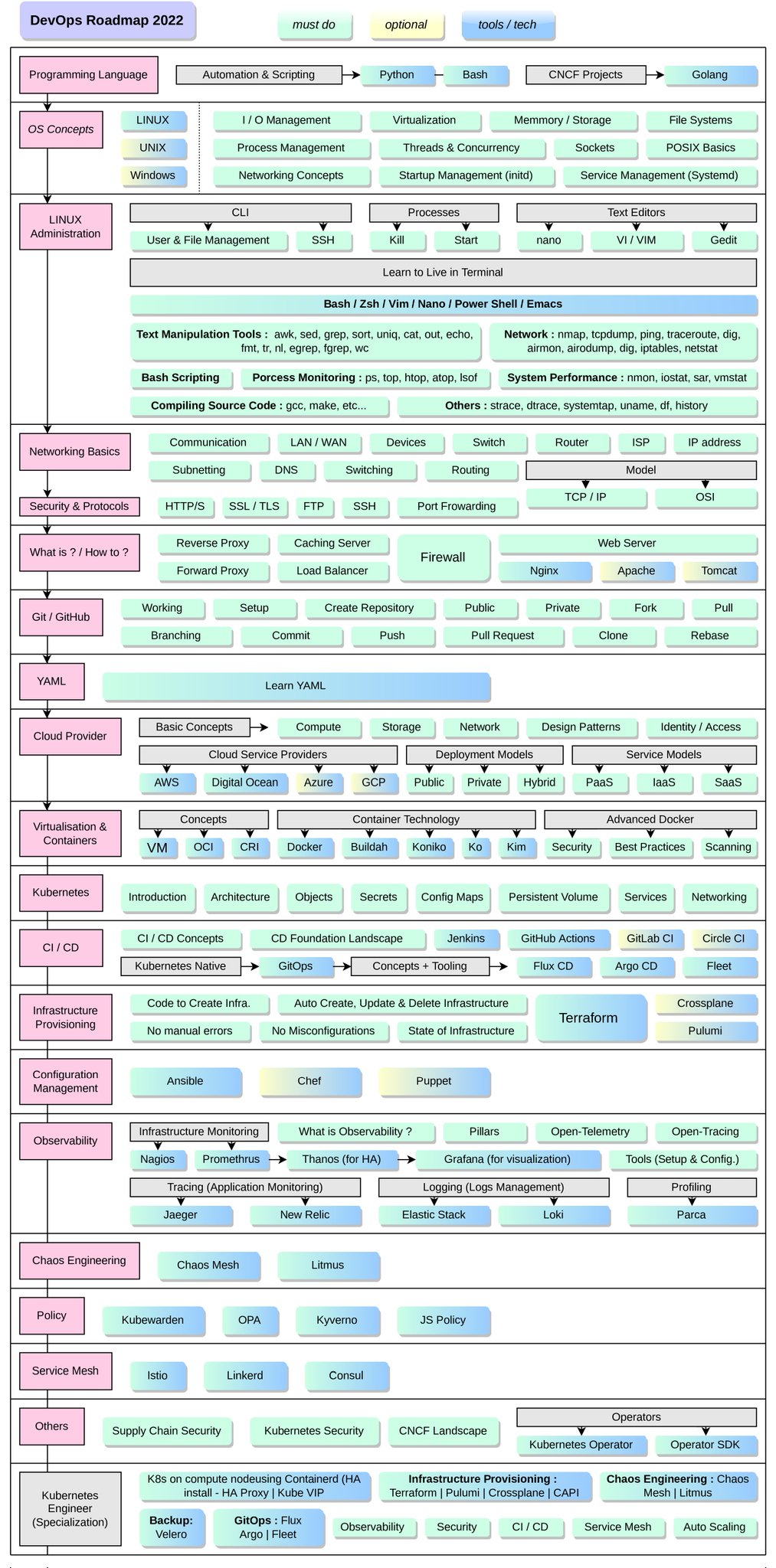
Best Resources for DevOps | 5 min read | DevOps | Java Revisited | Twitter
A collection of meaty DevOps materials, like this Road Map by Vrashabh Sontakke
TOOLS
Modin: Scale your Pandas workflows by changing a single line of code | 10 min to dig GitHub
Modin is a drop-in replacement for pandas. While pandas is single-threaded, Modin lets you instantly speed up your workflows by scaling pandas so it uses all of your cores. Modin works especially well on larger datasets, where pandas becomes painfully slow or runs out of memory.
By simply replacing the import statement, Modin offers users effortless speed and scale for their pandas workflows.
DataTube
From Nothing to Something: Klarna’s Journey With Recommendation Systems | 24 min | Anil Sharma | GAIA
Klarna’s journey from zero recommendation models to a state of five use cases in one year.
A recording from the GAIA Conference 2022.
CONFS AND MEETUPS
DATAMASS SUMMIT | 29-30 September | Gdańsk
To specify the subject of the summit: Big Data, Data Science, Machine Learning and AI, all in the context of cloud solutions.
One-day workshops, a one-day conference. A lot of case studies are planned for this event.
A few points from the agenda:
- How to process 33bln events from set top boxes in under 4 minutes
- Data engineering at the scale of PepsiCo eCommerce, 3 years of experience
- Data Platform - what does it take to be called a modern one? A new stack with well-known best practices
- The Data Mesh concept, executed by Trino
- Spark vs. Bigquery vs. Trino: Shopify’s journey of SQL transformations at scale
Remember about 10% discount with code: DATAPILL10!
PS, maybe there will be a chance to meet and network in our community?