
As I'm getting more and more referrals of content from you guys,
it would be great to have a place where we can stay in touch and exchange content easily.
So, we have created just that kind of a place.
👉 I invite you to join DATA Pill 💊 GitHub
and to submit content for the newsletter.
Any meaty content you submit by Thursday will appear in the Friday edition of this mailing!
And now: DATA Pill 23!
ARTICLES
Skyplane: 110x faster data transfers on any cloud | 5 min | Cloud Transfer | Paras Jain, Sarah Wooders & Joseph Gonzalez | Medium
Skyplane is an open-source developer tool for transferring data across cloud object stores. Skyplane is 164x faster than rsync and 113x faster than AWS DataSync.
It's amazing how a simple concept can provide such a boost. The VMka starts so fast that there is no need to think twice when copying a large volume.
Why Spotify Moved From Luigi to Flyte to Power Their 20,000+ Daily Workflows | 5 min | Workflow | Emil Bring | Heroes of Data Blog
Based on a presentation by Sonja Ericsson from Spotify.
Most of the data pipelines in Spotify relied on a tool called Luigi, which was built in-house by Spotify and open-sourced in 2012. In essence, it is a client-side orchestration framework (with a server scheduler) used to build data pipelines in Python. Due to increasing scale orchestration demands, Spotify decided to go with Flyte which was built by Lyft and open-sourced in 2020.
This article shows why and how.
How Fivetran actually fails saga | 20 min | Fivetran Airbyte, dbt & MDS | Lauren Balik | Medium Blog | Part1 > Part2 > Part3(!)
That will be not 1 but 3 articles (there is also something about Airbyte, dbt & MDS in general).
Get some 🍿 ready, as Fivetran's CEO definitely got on the wrong side of the author (check Part 3).
The whole saga initiated by the author is not only about Fivetran, but in general about the things that can be easily forgotten when deciding about MDS. Note for example how "over-normalization" and a subtle change of # of connectors to Monthly Active Row impacted the pricing. There is a 'T' before the L in the ELT — the decision by the EL provider to create as highly normalized as possible landing tables.
Report: 81% of IT teams directed to reduce or halt cloud spending by C-suite | 3 min read | Cloud | Wancloud | VentureBeat Blog
Based on a report by Wancloud.
The report reveals that IT decision-makers are taking action to rein in costs, with 39% noting they’ve decided to move or leave significant cloud consumption and high-performance workloads on premise, and a further 29% noting they’ve switched public cloud providers in the first half of 2022 due to high costs.
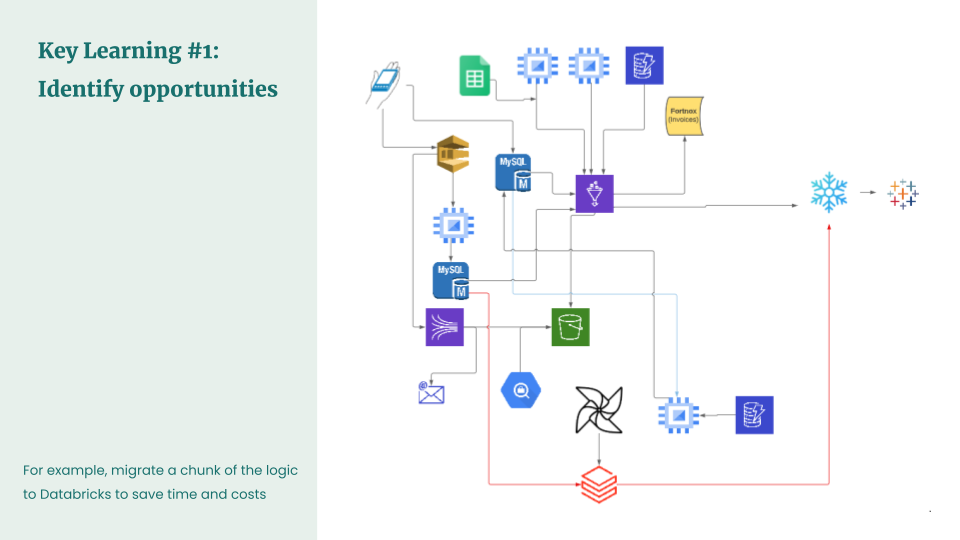
Scaling and migrating modern data services at logistics tech leader Budbee | 7 min read | ETL pipeline | Sara Landfors | Heroes of Data Blog
Based on Ji Krochmal's experience in building a new ETL pipeline—basically from scratch in Budbee.
In the old pipeline, there was ETL logic running in Airflow. It was quite slow because it was implemented in Python, and because it duplicated a lot of data (10K-100K times). As a consequence, it used a lot of AWS resources, and it was then queried by Athena without partitioning, which was expensive. Ji identified the opportunity to migrate all of this logic wholesale to Databricks, which ended up being a smart move. As a result, the old pipeline became much faster, used fewer resources, and was much easier to improve—while leveraging the logic and toolset of the new pipeline. The new system can be seen in the picture below, with the red line showing the new connections.
Data-driven fast-track: 3 steps to make your company more data-driven | 11 min | Analytics | Piotr Menclewicz | GetInData Blog
Piotr describes the 3 steps through the data journey you can take to become a more data-driven company.
How to Profile PySpark | 5 min read | Apache Spark | Xinrong Meng, Takuya Ueshin, Hyukjin Kwon & Allan Folting | Databricks Blog
PySpark UDFs offer flexibility since they enable users to run arbitrary Python code on top of the Apache Spark™ engine. Users only have to state "what to do", whereas PySpark, as a sandbox, encapsulates "how to do it". That makes PySpark easier to use, but it can be difficult to identify performance bottlenecks and apply custom optimizations.
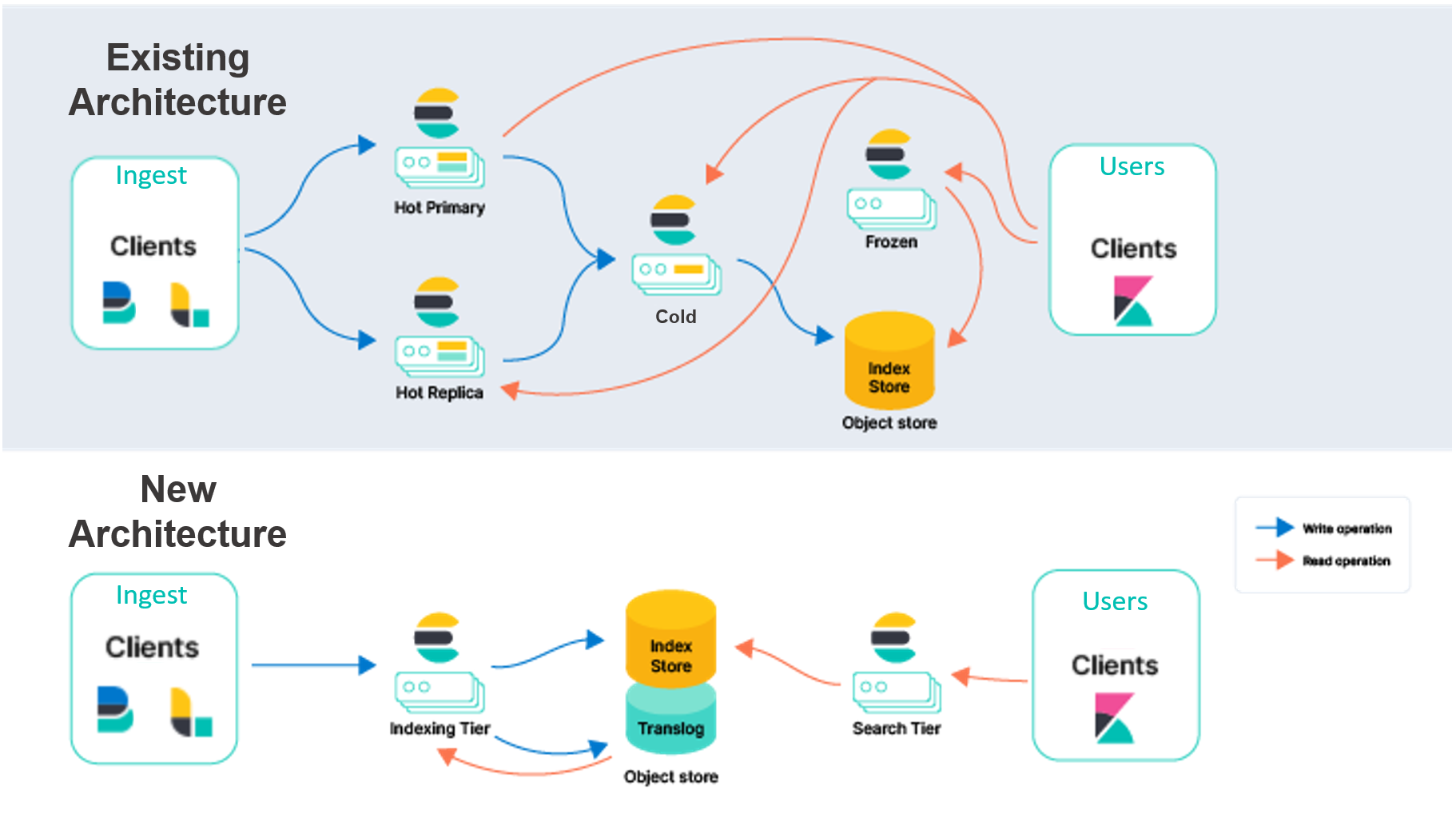
Stateless — your new state of find with Elasticsearch | 7 min | Elasticsearch | Leaf Lin, Tim Brooks & Quin Hoxie | Elastic Blog
Elasticsearch architecture is evolving. The new architecture enables many immediate and future improvements, including:
- You can significantly increase ingest throughput on the same hardware, or to look at it another way, significantly improve efficiency for the same ingest workload. This increase comes from removing the duplication of indexing operations for every replica. The CPU-intensive indexing operations only need to happen once on the indexing tier, which then ships the resulting segments to an object store. From there, the data is ready to be consumed as-is by the search tier.
- You can lower storage costs associated with search queries. By making the Searchable Snapshots model the native mode of searching data, the storage cost associated with search queries will significantly decrease. Depending on the search latency needs for users, Elasticsearch will allow adjustments to increase local caching on frequently requested data.
NEWS
Introducing Velox: An open source unified execution engine | 7 min | Data Infrastructure | Pedro Pedreira, Masha Basmanova, Orri Erling | Meta
Meta introduces Velox, an open source unified execution engine aimed at accelerating data management systems and streamlining their development.Velox helps consolidate and unify data management systems.
Introducing the Fleet Public Preview | 3 min | Hadi Hariri | The JetBrains Blog
The first public preview of Fleet, accessible to everyone. Fleet is our new distributed polyglot editor and IDE.
DATA ODDITY
Ubisoft's Low-Cost Deep Learning Model for Natural Character Movement | 3 min | Deep Learning | Arti Burton | 80 level Blog
A new advanced system for character animation from Ubisoft in France and Concordia University in the United States. The team developed a deep learning model for in-game character animation that allows developers to automatically generate natural character animation, reducing time costs.
Software Engineering at Google – book review | 9 min read | Software Engineering | Marcin Kuthan | Passionate Developer Blog
This is a review of “Software Engineering at Google” curated by Titus Winters, Tom Manshreck and Hyrum Wright with takeaways and personal conclusions from the book, like:
Hyrum’s law - ubiquitous law, referenced many times in the book.
With a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody.
For example, Linux wraps process identifiers (PID) when they exceed 32768 (2^15). Even if you can set the higher value, it would break because many libraries assume that the maximum is 32768.
PODCAST
Investing In Understanding The Customer Journey At American Express - Episode 331 | 40 min | Cloud | hosts: Tobias Macey; guests: Purvi Shah | Data Engineering Podcast
Purvi Shah, the VP of Enterprise Big Data Platforms at American Express, explains how they have invested in the cloud to power this visibility and the complex suite of integrations they have built and maintained across legacy and modern systems to make it possible.
CONFS EVENTS AND MEETUPS
QCon | 24-28 October | San Francisco
InfoQ Conference that gathers software leaders at early adopter companies, presenting the trends and practices.
Subsurface LIVE 2023 The Open Lakehouse Conference | 1-2 March 2023 | online | Call For Presentation till 31 0ctober
Speak up on The Open Lakehouse Conference.
The conference is related to data lakes and lakehouses, as well as data and analytics more broadly (e.g., last time, Wayfair spoke about their streaming analytics architecture). For data practitioners.
