ARTICLES
Direct Data Sharing using Delta Sharing - Introduction: Our Journey to Empower Partners at Zalando | Data Governance | 5 min | Lokeshbabu Radhakrishnan | Zalando Engineering Blog
Zalando is rolling out Delta Sharing to give partners real-time, governed access to data. No more manual exports, just scalable interoperability across teams and systems.
Azure’s Role Roulette: How Over-Privileged Roles and API Vulnerabilities Expose Enterprise | 10 min | Cloud | Ariel Simon | Token Security Blog
What happens when cloud roles are over-permissioned and APIs aren't locked down? This post breaks down how enterprise networks become vulnerable through misconfigured Azure IAM. Eye-opening stuff for platform and infra teams.
Stop Building AI Agents | 7 min | LLM | Hugo Bowne-Anderson | Decoding ML Blog
A sharp, opinionated take that argues most AI agents are unreliable and overhyped. Instead of building fragile generalists, this piece urges you to focus on narrow, robust tooling.
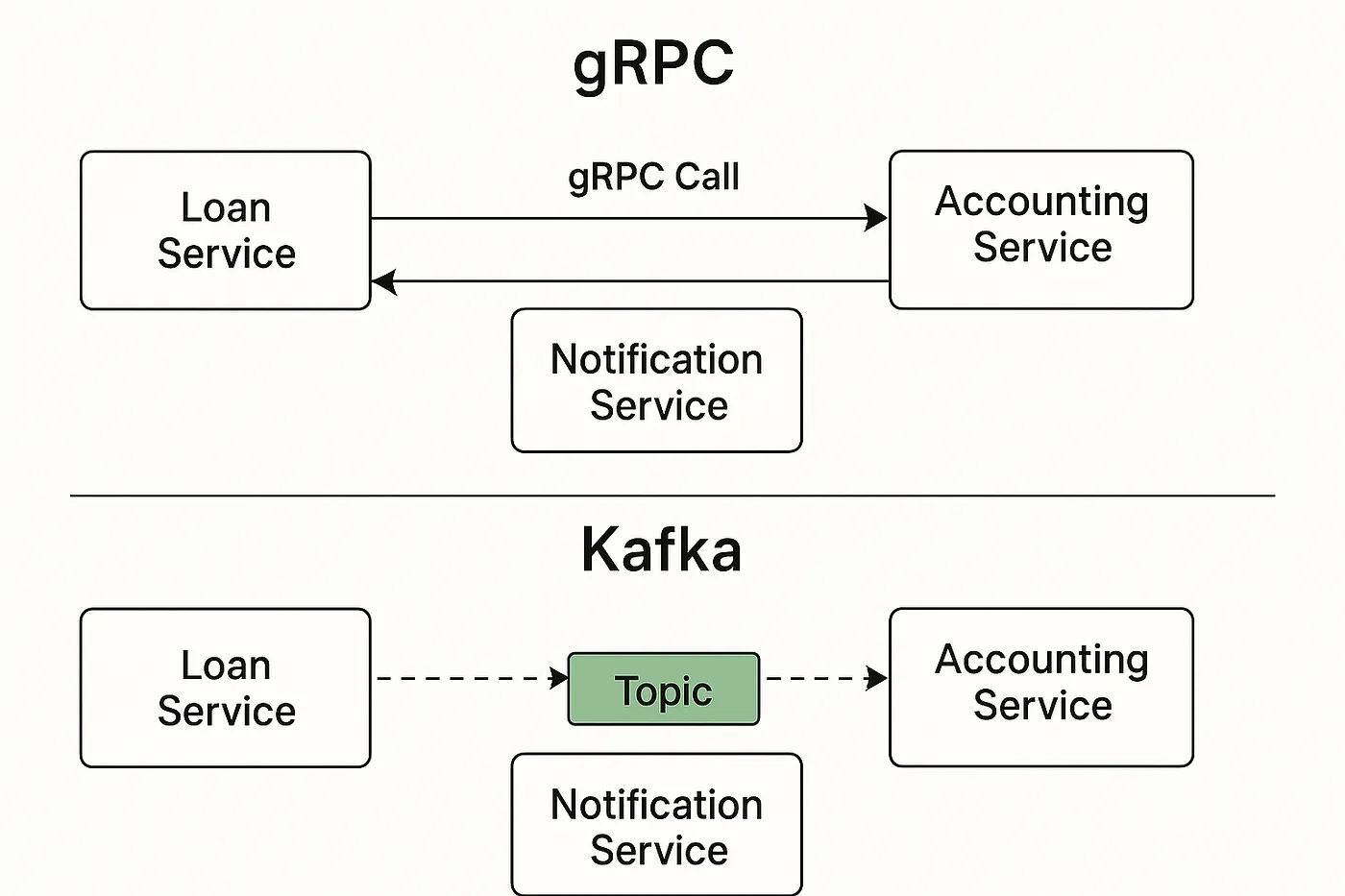
Why We Replaced Kafka with gRPC for Service Communication | 5 min | Data Engineering | Himanshu Singour | Personal Blog
One team ditched Kafka in favor of gRPC to reduce latency and simplify infra. A thoughtful case study that challenges default architectural choices.
What Is a Data Intelligence Engineer? | 3 min | Data Engineering | Scott Bell | My Year In Data Blog
An emerging role that blends engineering with metadata, usability, and making data discoverable. Think beyond pipelines.
TUTORIALS
Fine-Grained Authorization in Databricks with Unity Catalog | 4 min | Data Governance | Maurice Veltman | Xebia Blog
Learn how to implement secure, role-based access control in Databricks down to the column and row level.
How to Build AI Agents with Long-Term Memory Using Vertex AI | 4 min | LLMops | Ivan Nardin | Google Cloud Community Blog
Give your GenAI systems real memory using Vertex AI and vector databases. This tutorial walks through building agents that remember context across sessions.

NEWS
Introducing DataFrame API Support for Table-Valued Functions in Databricks | 5 min | Data Frames | Allison Wang, Takuya Ueshin, Jules Damji | Databricks Blog
You can now reuse complex logic with parameterized TVFs directly in the DataFrame API. Write cleaner pipelines without losing SQL-style reusability.
DATA TUBE
The future of Data & AI with David Meyer SVP Product at Databricks | 38 min | Data & AI | Quentin Ambard, David Meyer | NextGenLakehouse
David Meyer, SVP of Product, breaks down where Databricks is going next. From Lakehouse to AI-native tooling, this is a great listen for anyone working on next-gen data platforms.
CONFS, EVENTS AND MEETUPS
Cost-efficient cloud infrastructures for AI workloads | Webinar | June 15th
This session explores how to scale GenAI workloads using GPU-optimized cloud setups. Learn how to balance speed, cost, and reliability with both hyperscalers and new AI-native providers.
PINNACLE PICKS
Your last week top picks:
Model Once, Represent Everywhere: UDA (Unified Data Architecture) at Netflix | 15 min | Data Management | Alex Hutter, Alexandre Bertails, Claire Wang, Haoyuan He, Kishore Banala, Peter Royal, Shervin Afshar | Netflix Engineering Blog
Netflix introduces its Unified Data Architecture to power batch, streaming, and ML pipelines across a scalable and modular platform.
A new open-source Python notebook for building reactive dashboards with reproducible, modular code and minimal boilerplate.
Scaling Pinterest ML Infrastructure with Ray: From Training to End-to-End ML Pipelines | ML | 8 min | Andrew Yu, Jiahuan Liu, Qingxian Lai, Kritarth Anand | Pinterest Engineering Blog
Pinterest unified its ML stack using Ray to enable scalable training, hyperparameter tuning, and modular end-to-end pipelines.
________________________
Have any interesting content to share in the DATA Pill newsletter?