
ARTICLES
Gartner’s AI Hype Cycle is Way Passed its Due Date — And Are We Entering a Classical ML Winter? | 11 min | ML | Oliver Molander | Personal Blog
This one underscores the significance of prioritizing data quality and notes the existence of a "Classical ML" winter, challenging the prevailing narrative around Large Language Models (LLMs). The author advocates a well-balanced approach, incorporating Generative AI and Classical ML based on the specific use cases.
Kubernetes And Kernel Panics | 6 min | Kubernetes | Kyle Anderson | Netflix Engineering Blog
This blog post shows how to connect the dots from the worst case scenario (a kernel panic) through to Kubernetes (k8s) and eventually up to us operators so that we can track how and why our k8s nodes are going away.
Running Unified PubSub Client in Production at Pinterest | 13 min | Data Infrastructure | Jeff Xiang, Vahid Hashemian, Jesus Zuniga | Pinterest Engineering Blog
Read how Pinterest's PubSub Client has revolutionized data transport, enhancing development speed, stability and scalability. Critical features like automated service discovery and optimized configurations have substantially reduced setup time and Flink application restarts. Over 90% of Java applications seamlessly migrated to PSC, and plans include error handling improvements, cost attribution and support for C++ and Python.
BIZ
Why is streaming data and real-time AI critical in telecom? | 5 min | AI | Adam Kawa | GetInData | Part of Xebia Blog
Dive into the dynamic intersection of streaming data and real-time AI in the telecom industry. Explore how these technologies are changing how networks work, developing user experiences and pushing the telecom industry forward.
Applied Generative AI for Enterprise | 5 min | AI | Erika Lyxell, Fredrik Öström, Tomas Keller, Johan Vallin, Rickard Wieselfors | Ericsson Blog
The text explores Generative AI's capabilities, highlighting the transformer model and the evolution of models like GPT-4 and BERT. It discusses GenAI's implementation within Ericsson, showcasing practical use cases such as intelligent assistants, coding buddies and improved intelligent search.
TUTORIALS
Building a Data Streaming Pipeline: Leveraging Kafka, Spark, Airflow, and Docker | 11 min | Data Streaming | Simardeep Singh | Personal Blog
This tutorial details the construction of a strong data pipeline with Kafka, Spark, Airflow, Docker, S3 and Python. Using the Random Name API for real-time data, a Python script fetches and bridges data to Kafka, seamlessly running through Airflow DAGs. Spark Structured Streaming processes and writes data to S3, showcasing a modular architecture with Docker for smooth interoperability, scalability and debugging.
dbt Quicktip: Using deprecation_date to improve your model governance | 7 min | Cloud | Lucas Ortiz | Xebia Blog
Dive into the dbt feature "deprecation_date" for model governance in multi-project deployments, emphasizing its impact on change management. By setting this parameter in model definitions, warnings are generated for deprecated models, aiding in communication and facilitating long-term support plans, with the option to escalate warnings to errors for enhanced attention to deprecation dates.
Python Dependency Management in Spark Connect | 5 min | Data Engineering | Hyukjin Kwon, Ruifeng Zheng | Databricks Blog
This tutorial discusses the comprehensive approach to controlling Python dependencies during runtime using Spark Connect in Apache Spark.
NEWS
Block Public Sharing of Amazon EBS Snapshots | 4 min | Cloud | Jeff Barr | AWS Blog
This update introduces the capability of preventing the public sharing of Amazon Elastic Block Store (EBS) snapshots on a per-region, per-account basis, enhancing protection against unintentional data exposure. Users can now quickly turn off public sharing through the AWS Management Console, AWS Command Line Interface, or the new EnableSnapshotBlockPublicAccess function, with the setting applied at the regional level and affecting snapshot visibility within minutes.
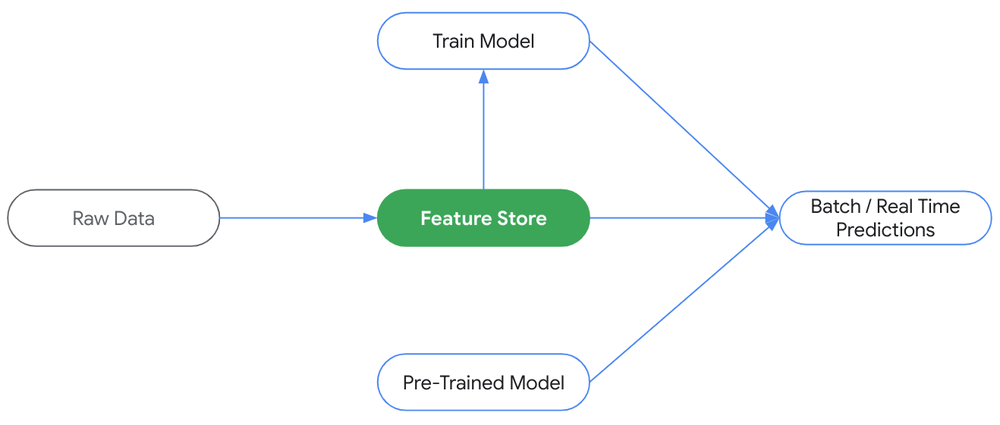
New Vertex AI Feature Store built with BigQuery, ready for predictive and generative AI | 5 min | AI | Raiyaan Serang, Alex Martin | Google Cloud Blog
Vertex AI is Google Cloud's all-in-one machine learning platform, including data engineering, science, and ML workflows. The Vertex AI Feature Store, in public preview, integrates with BigQuery for scalable predictive and generative AI. New real-time serving options offer low-latency feature lookups, and vector retrieval functionality adds native embeddings support to the feature store.
TOOLS
Create-llama, a command line tool to generate LlamaIndex apps | 2 min | AI | LlamaIndex Blog
Want to use the power of LlamaIndex to load, index and chat with your data using LLMs like GPT-4? It just got a lot easier! Llama created a simple-to-use command-line tool to generate a full-stack app for you — bring your data!
DATA TUBE
The more, the merrier: Managing a dynamic, expanding, self-service dbt project | 30 min | Data Engineering | Alice Leach | dbt
At Whatnot, the dbt project expanded from three to 50 developers and under 50 to over 1000 models in a year. Alice Leach, a data engineer, discusses the team's insights and solutions for scaling challenges, covering guard rails (CI/CD, model monitoring, and clean-up), guidelines (modular workspaces, macros, and documentation), and gadgets (dbt code generation and interfacing with other tools).
PODCAST
Shining Some Light In The Black Box Of PostgreSQL Performance | 55 min | SQL | Tobias Macey, Lukas Fittl | Data Engineering Podcast
Databases are the core of most applications but are often treated as mysterious black boxes. When an application is slow, there is a reasonable probability that the database needs some attention. In this episode, Lukas Fittl shares some hard-won wisdom about the causes and solutions of many performance bottlenecks and the work that he is doing to shine some light on PostgreSQL to make it easier to understand how to keep it running smoothly.
CONFS EVENTS AND MEETUPS
How to talk to your DATA with (or without) LLM | Webinar | 30th November
This webinar will give you a brief understanding of the essential challenges to measuring, managing and discussing business problems across the organization layers and the key to overcoming them.
What we will discuss:
- Challenges in independently accessing data analysis by decision-makers
- What is a data model? And why it matters
- Why the generation of SQL is not enough to achieve value from data
- Looker and data model management
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
