
ARTICLES
Keeping track of shipments minute by minute: How Mercado Libre uses real-time analytics for on-time delivery | 12 min read | Data Analytics | Pablo Fernández Osorio | Mercado Libre | Google Cloud Blog
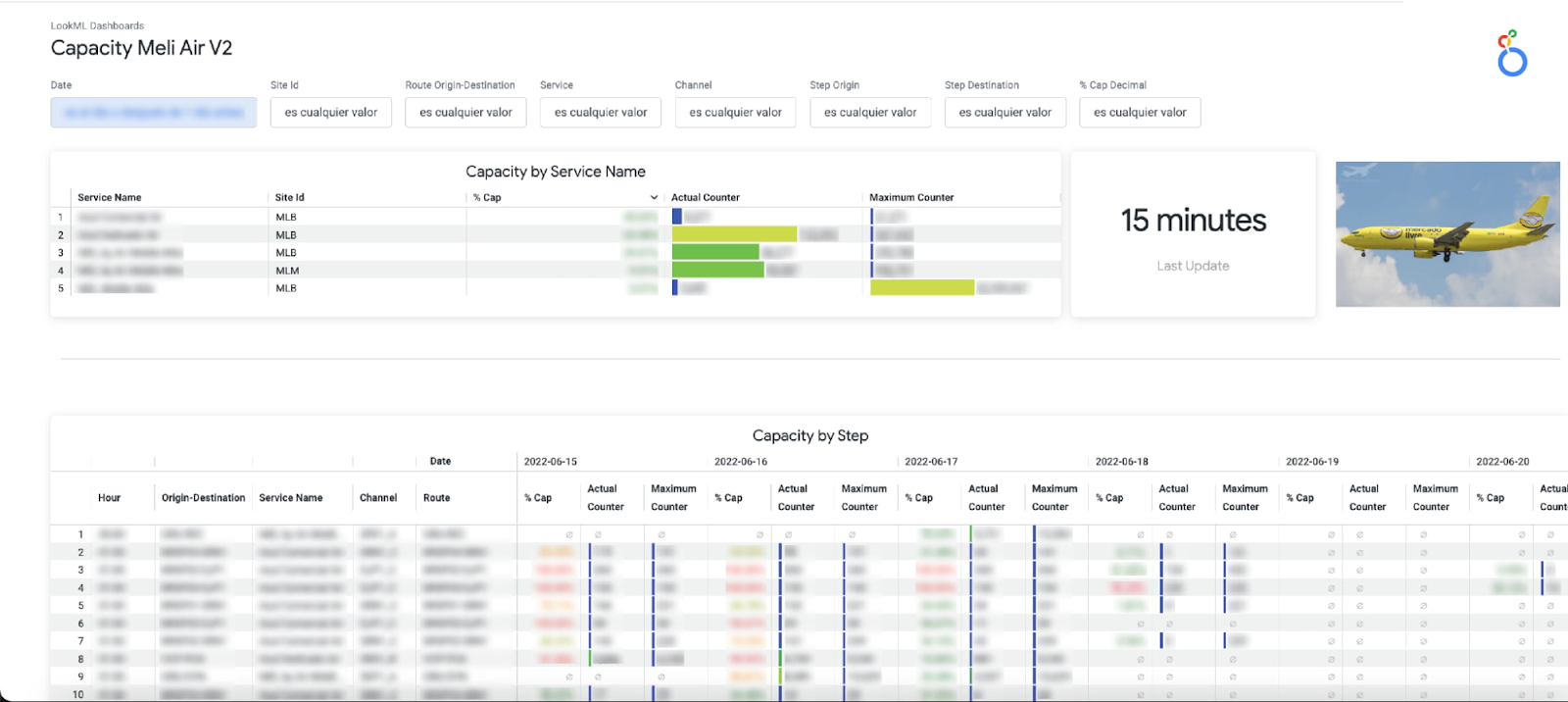
Mercado shares a continuous intelligence framework that enables them to deliver 79% of our shipments in less than 48 hours (due to increased demand).
Data used to support decision-making in key processes:
- Carrier Capacity Optimization - monitor the percentage of network capacity utilized across every delivery zone and identify where delivery targets are at risk in almost real time.
- Outbound Monitoring - enables them to identify places with lower delivery efficiency and drill into the status of individual shipments.
- Air Capacity Monitoring - Provides capacity usage monitoring for aircrafts running each of our shipping routes.
Airflow's Problem | 7 min read | Airflow | Stephen Bailey | Data People Etc.
Let’s put the cat amongst the pigeons ;) Why the author doesn’t like Airflow and disputes the data mesh times we should seek as an alternative.
Google Introduces Zero-ETL Approach to Analytics on Bigtable Data Using BigQuery | 7 min read | Cloud | Steef-Jan Wiggers | InfoQ Blog
Previously, customers had to use ETL tools such as Dataflow or self-developed Python tools to copy data from Bigtable into BigQuery; however, now they can query data directly with BigQuery SQL.
Recent Research From Harvard and Keio University Researchers Present A New Link Between Dopamine-Based Reward Learning And Machine Learning | 5 min read | GCP & Kafka | Pushpa Baraik | Marktechpost Blog
To develop effective machine learning models that can handle challenging tasks, computer scientists have recently started attempting to artificially reproduce the neurological foundations of reward learning in mammals. The so-called temporal difference (TD) learning algorithm is a well-known machine learning technique that mimics the operation of dopaminergic neurons.
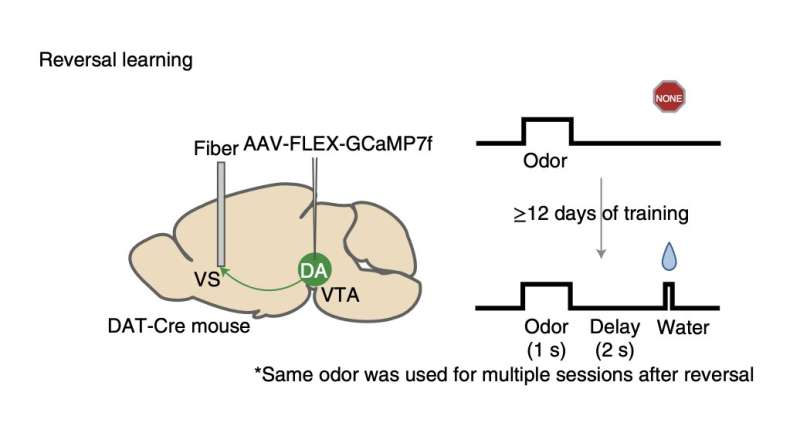
Amo et al. | Source: https://www.nature.com/articles/s41593-022-01109-2
NEWS
Python models | 10 min read | Databricks Blog
Update on the future feature of dbt, python models.
A dbt Python model is a function that reads in dbt sources or models, applies a series of transformations and returns a transformed dataset. DataFrame operations define the starting points, the end state and each step along the way. This is similar to the role of CTEs in dbt SQL models.
Apache Flink Source Connector for Delta Lake tables | 7 min read | Cloud | 💪 Krzysztof Chmielewski, Scott Sandre, Denny Lee | Delta Lake
The new release of Delta Connectors 0.5.0, introduces the new Flink/Delta Source Connector on Apache Flink™ 1.13 that can read directly from Delta tables using Flink’s DataStream API. Both the Flink/Delta Source and Sink connectors are now available as one JVM library that provides the ability to read and write data from Apache Flink applications to Delta tables using the Delta Standalone JVM Library.
Here you will find info about architecture and implementation.
TUTORIALS
Iceberg Tables: Powering Open Standards with Snowflake Innovations | 7 min read | Data Lake | James Malone | Snowflake
Snowflake is used to solve three challenges commonly related to large data sets: control, cost, and interoperability. Iceberg Tables combine unique Snowflake capabilities with the Apache Iceberg and Apache Parquet open source projects to solve this. This article explains how Iceberg Tables are supposed to help with that.
Introducing the Geoparquet data format | 11 min read | Big Data | 💪 Paweł Kociński | GetInData Blog
- Why there is a need for a unified format for geospatial data
- Parquet introduction
- The goals and features of Geoparquet
- Why Geoparquet could be the future of geospatial data processing at scale
PODCAST
Future-Aware Data Engineer | 42 min | Data Engineering | 💪 Paweł Leszczyński | GetInData
Will this go viral? It’s already widely commented and shared material. …
It is the story of past and current inventions like Facebook by Mark Zuckerberg vs the airplane by the Wright brothers. What is the Dunning-Krueger effect and what does it have in common with Wikipedia? Why did Jacek Kuroń not have to pay his phone bills? We're going to look at these inventions through the lens of Yuval Noah Harari, Daniel Kahneman, and Slavoj Zizek. Seems like the perfect authors' trio for the ideal data-related holiday podcast.
Post-Deployment Data Science | 33 min | ML | Hakim Elakhrass | DataCamp
Many machine learning practitioners dedicate most of their attention to creating and deploying models that solve business problems. However, what happens post-deployment? Moreover, how should data teams go about monitoring models in production?
Takeaway: Data scientists need to cultivate a thorough understanding of a model’s potential business impacts, as well as the technical metrics of the model.
DataTube
WHOOPS, THE NUMBERS ARE WRONG! SCALING DATA QUALITY NETFLIX | 0,5 h | Michelle Ufford | Netflix | DataWorks Summit
We just found out that there exists a named development pattern of data pipeline DAGs that concern data quality called “Write-Audit-Publish”.
It’s like “blue-green deployment but for data”. I know, it’s obvious, but hey, it’s good to have names for simple things ;)
The original name shows up in this Netflix presentation.
You’re probably curious about how people apply this pattern in tools like dbt.
We only found one video and some slides:
dbt Office Hours: BigQuery + dbt | 1 h | Claus Herther, Rasmus Bjerrum | dbt |
and slides:
How do I keep bad data from being published in my dashboard? | PDF slides | Claus Herther | Calogica
If you know of some interesting sources on this subject, please write to datapill@getindata.com ;)
CONFS AND MEETUPS
How to simplify data and AI governance | 16 August | Online | databricks & Milliman
- How to manage user identities, set up access permissions and audit controls, discover quality data and leverage automated lineage across all workloads
- How to securely share live data across organizations without any data replication
- How Databricks customer Milliman is leveraging Unity Catalog to simplify access management and reduce storage complexity
Speakers: Paul Roome, Liran Bareket, Dan McCurley
