
ARTICLES
Transactions Aren’t Enough: The Need for End‑to‑End Thinking | Arkadiusz Chmura | Allegro Tech | 10 min | Data Architecture
Allegro’s Arkadiusz Chmura argues that ACID transactions and high‑isolation levels still can’t prevent data loss in distributed systems. Using a budget reallocation example, he shows how network failures and retries can result in duplicate writes and inconsistent state. The solution is to introduce idempotent operation identifiers and treat every request as an event written to a log; derived tables such as budgets then become views over a source‑of‑truth event log, updated asynchronously
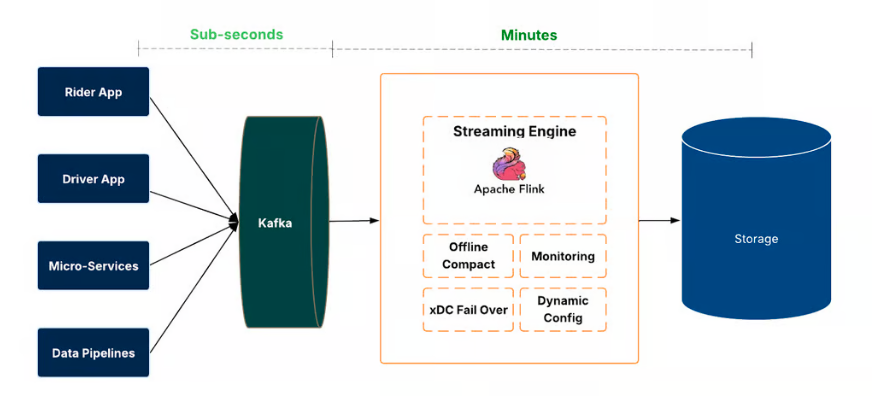
From Batch to Streaming: Accelerating Data Freshness in Uber’s Data Lake | Xinli Shang, Peter Huang, Jing Li, Jing Zhao, Jack Song |Uber Engineering | 8 min | Streaming Systems
Uber re‑architected its data‑lake ingestion to support streaming, moving from hourly batch jobs to continuous Flink‑based pipelines. The new system, IngestionNext, reduces data latency from hours to minutes and enables fresher, more consistent views of operational data, while smoothing resource utilization and lowering costs.
How Pinterest Built a Real‑Time Radar for Violative Content Using AI | Faisal Farooq, Aravindh Manickavasagam & Attila Dobi | Pinterest Engineering | 7 min | Real-Time
Pinterest’s trust & safety team measures prevalence—the share of user impressions that violate policy—to understand the true scale of harmful content. They built a real‑time AI‑assisted workflow that samples daily impressions and uses human review plus machine learning to estimate prevalence
From Python 3.8 to 3.10: Our Journey Through a Memory Leak | Jay Patel| Lyft Engineering | 8 min | Data Science
Upgrading Lyft’s services from Python 3.8 to 3.10 exposed a memory leak triggered by reference cycles and caching in long‑running processes. Jay Patel recounts how engineers used tracemalloc and objgraph to identify the leak, discovered it was tied to lazy initialisation and caches, and eliminated it by explicitly clearing caches.
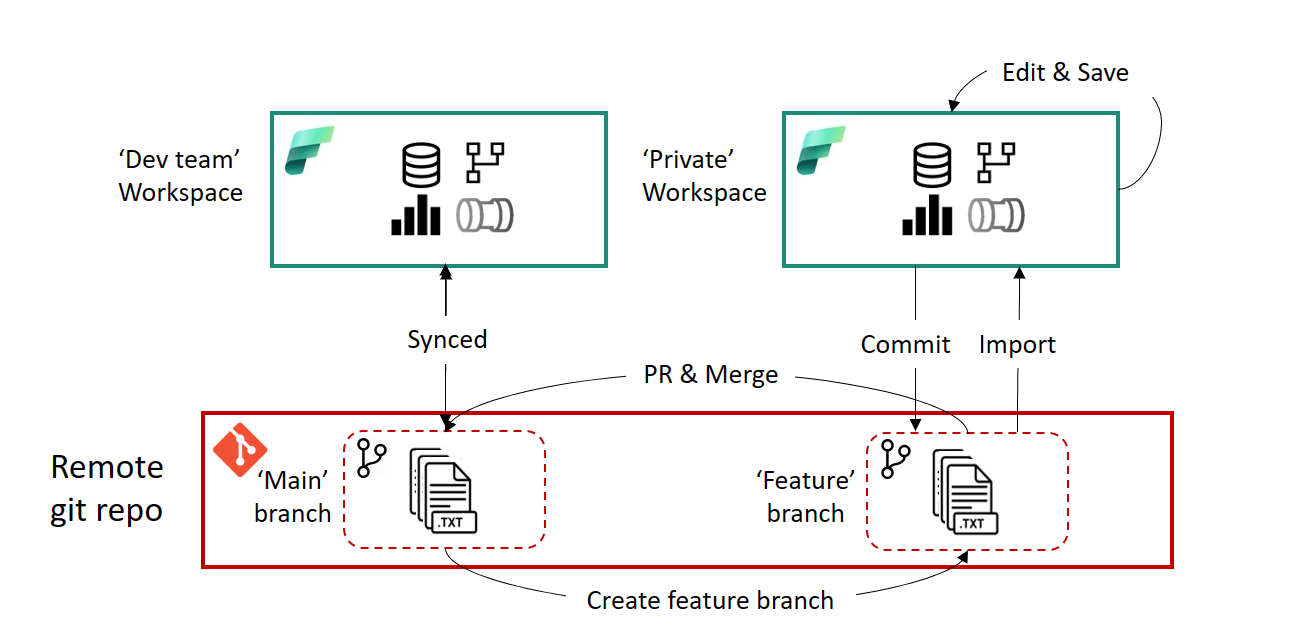
Microsoft Fabric Workspace Setup for Multi‑Developer Teams | Rik Adegeest | Xebia | 11 min | Governance
When multiple developers work in Microsoft Fabric, a single workspace quickly becomes a bottleneck. Rik Adegeest explains how to organise Fabric projects across multiple workspaces and Git branches to enable parallel development, avoid excessive cloning and keep Lakehouse artifacts in sync
NEWS
Spotify Lets You Steer the Algorithm With Prompted Playlists | Gustav Söderström | Spotify | 6 min
Spotify’s Prompted Playlist beta allows Premium listeners in New Zealand to generate playlists by describing what they want to hear. Users type natural‑language prompts—like “music from my top artists from the last five years” or “high‑energy hip‑hop for a 5K run”—and the algorithm taps into their entire listening history to curate a personalised mix. Playlists can refresh daily or weekly, and prompts can be refined or restarted on demand. Spotify frames this as a shift toward giving listeners direct control over the algorithm while still honouring human curation.
DoorDash Rolls Out Zesty, an AI Social App for Discovering New Restaurants | Aisha Malik | TechCrunch | 5 min
DoorDash launched Zesty, a standalone AI‑powered app that helps users find local restaurants. Available initially in the San Francisco Bay Area and New York, Zesty lets users chat with an AI to get personalised recommendations, aggregated from DoorDash, Google Maps, TikTok and other sources
TOOLS
Google’s Gemini 3 Flash model offers frontier‑class multimodal and agentic capabilities at less than one‑quarter the cost of Gemini 3 Pro. It delivers advanced visual and spatial reasoning, supports code execution and outperforms 2.5 Pro while being three times faster. Developers can access it via Google AI Studio, Antigravity, Gemini CLI, Android Studio and Vertex AI, with context caching and batch API support for cost‑efficient scaling
Zoom’s AI Companion 3.0 introduces agentic workflows and a new web interface that turns meeting conversations into actionable tasks and documents. The release includes personal workflows (beta), agentic retrieval across meeting summaries, transcripts and third‑party apps, prompt templates like Post Meeting Follow Up and Daily Reflection Report, and an agentic writing mode.
DATATUBE
[POLISH ONLY] Zbuduj Agenta AI na Bielik LLM – Pydantic AI Tutorial | Wojtek Mikołajczyk, Marcin Zabłocki | ML‑Workout | 20 min
This Polish‑language tutorial shows how to build an AI agent using the Bielik large language model and Pydantic for data validation. It walks through designing prompts, structuring agent loops and deploying the agent in an end‑to‑end workflow, making it ideal for developers interested in local LLMsConcurrent is a free desktop application that lets you benchmark over a thousand AI models across 30+ providers and local runtimes. You type a prompt and the tool sends it to multiple models, then displays responses side‑by‑side with metrics for quality, speed (tokens per second) and cost.
PINNACLE PICKS
Your last week top picks:
We Spent 2 Years Building a Data Mesh — It Was a $4M Disaster | Medium | Amįń | 9 min | Data Leadership
In this candid postmortem, a data engineer recounts how a two‑year, $4 million data‑mesh initiative turned into 47 competing fiefdoms. Despite following best practices and even consulting Zhamak Dehghani, the team ended up with worse data quality, unused “data products” and missed deadlines; they are now abandoning the mesh in favor of a centralized platform
Amazon Bedrock AgentCore Tutorial | Build, Deploy, Operate AI Agents using AgentCore | Dhaval Patel | Codebasic | ~32 min
This session explores the shift from monolithic models to agentic systems, focusing on how developers should structure orchestration layers, evaluation harnesses and safety guardrails for autonomous agents. Examples cover multi‑agent planning, tool selection and error handling.
AWS re:Invent 2025 | Special Closing Keynote with Dr. Werner Vogels | AWS | 1h
A live demo showing how to augment streaming data pipelines with generative AI and multi‑agent logic. The speaker builds an end‑to‑end pipeline that uses streaming context to feed real‑time agents, illustrating state management, observability and deployment patterns.
In this candid postmortem, a data engineer recounts how a two‑year, $4 million data‑mesh initiative turned into 47 competing fiefdoms. Despite following best practices and even consulting Zhamak Dehghani, the team ended up with worse data quality, unused “data products” and missed deadlines; they are now abandoning the mesh in favor of a centralized platform
Amazon Bedrock AgentCore Tutorial | Build, Deploy, Operate AI Agents using AgentCore | Dhaval Patel | Codebasic | ~32 min
This session explores the shift from monolithic models to agentic systems, focusing on how developers should structure orchestration layers, evaluation harnesses and safety guardrails for autonomous agents. Examples cover multi‑agent planning, tool selection and error handling.
AWS re:Invent 2025 | Special Closing Keynote with Dr. Werner Vogels | AWS | 1h
A live demo showing how to augment streaming data pipelines with generative AI and multi‑agent logic. The speaker builds an end‑to‑end pipeline that uses streaming context to feed real‑time agents, illustrating state management, observability and deployment patterns.
_____________________
Have any interesting content to share in the DATA Pill newsletter?
