
ARTICLES
LLM Apps Are Mostly Data Pipelines | 7 min | LLM | Pat Nadolny | Meltano Blog
While tools like LangChain and LlamaIndex help create LLM apps, their data loading capabilities could be more suitable for production. If you're building a robust data pipeline for LLM apps, using a dedicated EL tool is advisable.
How to Optimize FastAPI for ML Model Serving | 6 min | ML | Luis Sena | Personal Blog
This one touches on FastAPI for serving machine learning models, focusing on the shift from synchronous to asynchronous programming and the performance implications of combining I/O and CPU-bound tasks. It shows practical solutions, such as leveraging ProcessPoolExecutor, to ensure efficient I/O task handling while effectively managing concurrent requests.
How Whatnot Utilizes Generative AI to Enhance Trust and Safety | 6 min | LLM | Charudatta (CD) Wad | Whatnot Engineering
This blog discusses how Whatnot utilizes Large Language Models (LLMs) to enhance trust and safety areas, including a multimodal content moderation, fulfillment, bidding irregularities and general fraud protection.
Are You Using Elementary for DBT? | 4 min | Data Engineering | Leo Godin | Personal Blog
This article introduces Elementary, a versatile dbt package and CLI tool designed to simplify the management of data pipelines. It automatically maintains a comprehensive data mart containing essential project metadata, offers an intuitive dashboard for monitoring, and enables Slack alerts for effective communication within data teams, making it an invaluable tool for data and analytics engineers.
TUTORIALS
Chat with your data using OpenAI, Pinecone, Airbyte and Langchain | 14 min | Data Science | Joe Reuter | Airbyte Blog
This tutorial walks you through a real-world use case of how to leverage vector databases and LLMs to make sense out of your unstructured data. By the end of this, you will know how to:
- extract unstructured data from a variety of sources using Airbyte
- use Airbyte to efficiently load data into a vector database, preparing the data for LLM usage along the way
- integrate a vector database into your LLM to ask questions about your proprietary data
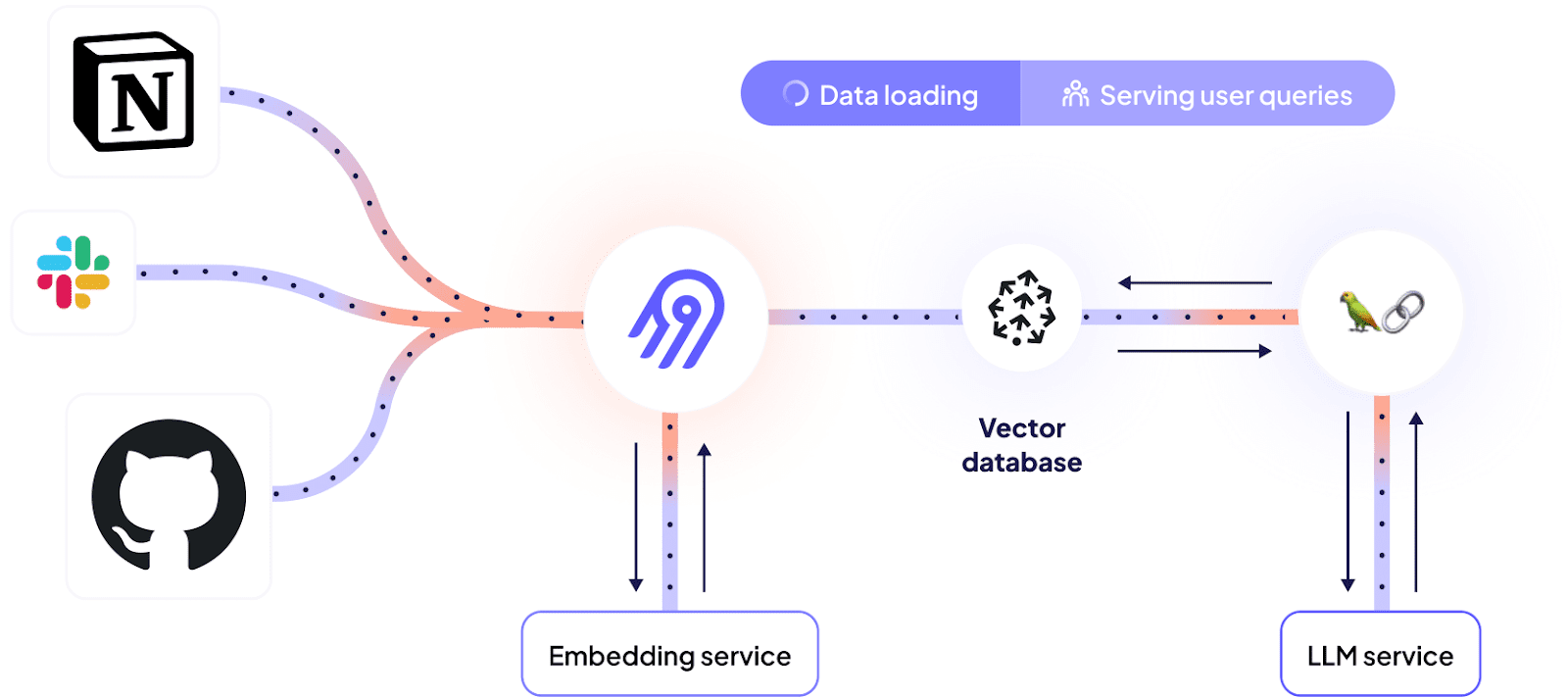
How to use LLMs for data enrichment in BigQuery? | 16 min | LLM | Piotr Pilis | GetInData | Part of Xebia Blog
In this tutorial, Piotr aims to provide a comprehensive guide on how individuals can leverage LLMs and BigQuery to bring additional value to their data and boost their analytical capabilities. They cover use-cases, architectural considerations, implementation steps and evaluation methods to ensure that readers are fully equipped to use this powerful combination in their own data processes.
NEWS
Coming Soon: Confidence — An Experimentation Platform from Spotify | 5 min | Data Engineering | Tyson Singer | Spotify Blog
Spotify introduces Confidence, a commercial product tailored for software development teams, offering an experimentation platform designed to facilitate user tests, including A/B testing and complex scenarios. With a focus on flexibility and scalability, Confidence aims to seamlessly integrate experimentation into organizations, drawing from Spotify's decade-plus experience in enabling large-scale experiments.
Deploy Private LLMs using Databricks Model Serving | 3 min | LLM | Ahmed Bilal, Ankit Mathur, Kasey Uhlenhuth and Joshua Hartman | Databricks Blog
Databricks Model Serving now offers GPU and LLM optimization support in public preview. You can deploy various AI models, including LLMs and Vision models on the Lakehouse Platform effortlessly, benefiting from automatic optimization for top-notch LLM Serving performance without the need for manual setup.
DATA TUBE
Making Better Decisions with Cassie Kozyrkov, Google's First Chief Decision Scientist | 1 h 13 min | Data Science | Cassie Kozyrkov | DataCamp
In this episode, Cassie and Richie explore the misconceptions around data science, stereotypes associated with being a data scientist, what the reality of working in data science is, advice for those starting their career in data science, and the challenges of being a data ‘jack-of-all-trades’.
PODCAST
Building ETL pipelines with Generative AI | 51 min | AI | host: Tobias Macey; guest: Jay Mishra | Data Engineering Podcast
In this episode, Jay Mishra delves into his experiences and knowledge gained from crafting ETL pipelines with the assistance of cutting-edge generative AI technology.
Addressed topics:And more.
- What are the different aspects/types of ETL that are seeing generative AI applied?
- What are the most interesting, innovative or unexpected ways generative AI is used in ETL workflows?
- What are the most interesting, unexpected or challenging lessons that Jay has learned while working on ETL and generative AI?
Transformative role of AI in education | 1 h 40 min | AI | hosts: Anders Arpteg & Henrik Göthberg; guest: Anders Enström | AIAW Podcast
This episode offers a comprehensive look at AI's role in learning and is a must-listen for those curious about the future of education.
CONFS EVENTS AND MEETUPS
MOPS - Meetup | Onsite | 10th October 2023
This meetup includes three 25-minute practical talks and a 5-minute question-and-answer session.
The presentations that will be given:
- Portable and cloud-agnostic MLOps Platform with Kedro, MLflow and Terraform
- Architecting ML for Huge Impact and Scale
- Building machine learning platforms for a living - lessons learned
Build conversational AI experiences powered by LLMs with Vertex AI Conversation and Dialogflow CX | Webinar | 24th October 2023
In this session, join Google Cloud Champion Innovator and Google Developer Expert in Machine Learning, Xavier Portilla Edo, and Developer Advocate, Alessia Sacchi, to learn:
- The latest Generative AI features in Vertex AI Conversation and Dialogflow CX
- How to combine traditional agent design techniques and best practices with Google's latest generative large language models (LLMs) to create complex conversational applications that are prepared to handle the many different ways that users might interact with it
- Examples of tasks that Conversational AI, Search and LLMs can solve, including demos
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
